DICEPTION: 하나의 Diffusion 모델로 모든 시각 지각 태스크 해결
DICEPTION
논문: DICEPTION: A Generalist Diffusion Model for Vision Perception
저자: Canyu Zhao, Mingyu Liu, Huanyi Zheng, Muzhi Zhu, Zhiyue Zhao, Hao Chen, Tong He, Chunhua Shen
기관: Zhejiang University, Shanghai AI Laboratory
논문 발표: 2025년 2월 25일
프로젝트 웹사이트: aim-uofa.github.io/Diception
Hugging Face 데모: DICEPTION-Demo

DICEPTION 모델 개요
DICEPTION은 Diffusion 모델 기반의 범용 비전 지각 모델입니다. 기존 컴퓨터 비전 모델들은 특정 태스크(예: 객체 탐지, 의미론적 분할, 깊이 추정)를 수행하는 개별적인 모델로 훈련되었지만, DICEPTION은 하나의 모델이 여러 태스크를 동시에 해결할 수 있도록 설계되었습니다.
기존의 범용 모델과 비교했을 때 DICEPTION의 가장 큰 특징은 적은 데이터로도 높은 성능을 유지할 수 있다는 점입니다. 예를 들어, SAM-vit-h 모델은 10억 개 이상의 픽셀 수준 주석 데이터로 학습되었지만, DICEPTION은 단 60만 개의 이미지 데이터만으로도 SAM과 동등한 성능을 보입니다.
DICEPTION이 해결하는 태스크
DICEPTION은 다음과 같은 시각 지각 태스크를 지원합니다.
- 깊이 추정 (Monocular Depth Estimation): 단일 이미지에서 3D 깊이 정보를 예측
- 표면 법선 추정 (Surface Normal Estimation): 이미지의 각 픽셀에 대한 표면 기울기 벡터를 예측
- 객체 분할 (Instance Segmentation): 이미지 내 객체별 경계를 구분
- 의미론적 분할 (Semantic Segmentation): 픽셀 단위로 객체 종류를 분류
- 포즈 추정 (Pose Estimation): 인체 및 물체의 2D/3D 위치와 자세를 예측
- 포인트 프롬프트 분할 (Point-Prompted Segmentation): 특정 점을 기준으로 영역을 분할


DICEPTION의 주요 특징
1. 단일 모델로 다양한 태스크 수행
기존 컴퓨터 비전 모델들은 각 태스크별로 개별적인 네트워크 구조를 사용해야 했습니다. 하지만 DICEPTION은 하나의 모델이 모든 태스크를 해결할 수 있도록 설계되었습니다.
- 동일한 Diffusion 모델을 활용하여 다양한 태스크를 일관된 방식으로 처리
- 태스크 간 파라미터 공유를 통해 추론 속도 향상 및 메모리 사용량 절감
- 특정 태스크를 수행하는 전용 모델(SAM, MiDaS, DepthAnything)과 비교해도 경쟁력 있는 성능 유지
2. 적은 데이터로도 높은 성능 발휘
DICEPTION은 60만 개의 데이터만 사용하고도, 10억 개 이상의 데이터로 학습된 SAM-vit-h와 비슷한 성능을 보입니다.
- 데이터가 제한적인 상황에서도 일반화 성능이 우수
- 모델이 학습한 태스크 외에도 Few-shot 및 Zero-shot 학습 가능
- 새로운 태스크로의 적응(Fine-tuning)이 빠르고 효율적
3. RGB 기반 태스크 표현 방식
DICEPTION은 모든 태스크의 출력을 RGB 이미지 형식으로 변환하여 일관된 출력을 유지합니다.
| 태스크 | 기존 모델 출력 | DICEPTION 출력 |
|---|---|---|
| 깊이 추정 | Grayscale Depth Map | RGB 변환 |
| 표면 법선 추정 | 벡터 필드 | RGB 변환 |
| 객체 분할 | 바이너리 마스크 | RGB 변환 후 클러스터링 |
| 의미론적 분할 | 범주별 마스크 | RGB 변환 후 K-Means 처리 |
이 방식 덕분에 모델의 구조가 단순해지고, 태스크 간 전이 학습(Transfer Learning)이 용이해졌습니다.
4. 빠른 적응(Few-Shot Learning & Fine-tuning)
DICEPTION은 매우 적은 데이터(50개 샘플)와 1% 미만의 가중치 업데이트만으로도 새로운 태스크에 적응할 수 있습니다.
즉, 새로운 데이터셋이 주어지더라도 전체 모델을 다시 학습할 필요 없이, 소량의 데이터로 빠르게 성능을 개선할 수 있습니다.
DICEPTION의 동작 원리
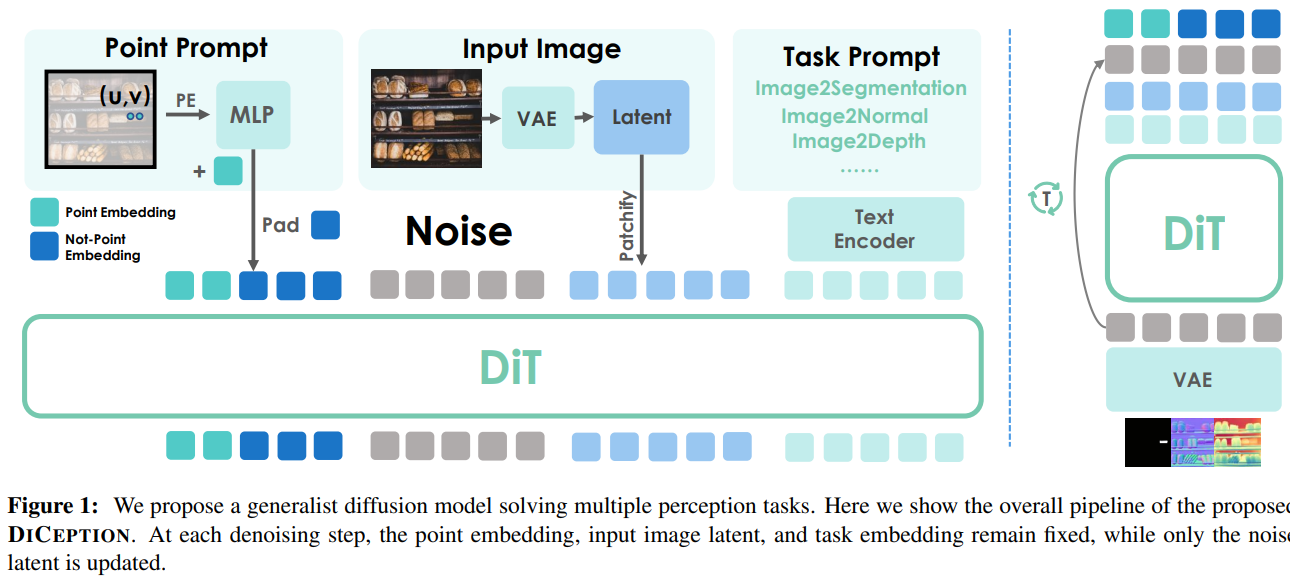
1. Diffusion 모델을 활용한 시각 지각 태스크 해결
DICEPTION은 확산 모델(Diffusion Model) 을 활용하여 시각 지각 태스크를 해결합니다. Diffusion 모델은 이미지 생성 및 복원에 강점을 가지며, 특히 다양한 태스크를 하나의 모델로 통합하는 데 유리한 구조를 제공합니다.
- 입력 이미지에 노이즈를 추가한 후, 원본 이미지를 복원하는 방식으로 훈련
- 훈련 과정에서 다양한 태스크(깊이 추정, 객체 분할 등)의 목표 출력을 학습
- 최종적으로, 주어진 입력에 대한 가장 적합한 태스크 출력을 생성하도록 모델이 최적화됨
2. 태스크별 데이터 매핑 방식
DICEPTION은 태스크별 목표 출력을 Diffusion 모델이 학습할 수 있도록 다양한 데이터 매핑 기법을 활용합니다.
| 태스크 | 입력 데이터 | 목표 출력 |
|---|---|---|
| 깊이 추정 | RGB 이미지 | RGB 깊이 맵 |
| 객체 분할 | RGB 이미지 | 색상 기반 분할 마스크 |
| 표면 법선 추정 | RGB 이미지 | 법선 방향이 인코딩된 RGB 맵 |
이 방식 덕분에 Diffusion 모델이 태스크별 출력을 일관된 방식으로 처리할 수 있으며, 적은 데이터로도 높은 성능을 유지할 수 있습니다.
3. 모델의 훈련 과정
DICEPTION의 훈련 과정은 크게 3단계로 나뉩니다.
- 사전 학습 (Pretraining)
- 대규모 범용 데이터셋을 활용하여 Diffusion 모델을 기본적인 시각 지각 태스크에 맞춰 훈련
- 다양한 태스크를 통합적으로 수행할 수 있도록 RGB 기반 태스크 표현 방식 학습
- 미세 조정 (Fine-tuning)
- 특정 태스크(예: 깊이 추정, 객체 분할)에 대한 추가 학습 진행
- 소량의 데이터로도 빠르게 적응 가능 (Few-shot Learning)
- 태스크 전이 학습 (Transfer Learning)
- 기존에 학습한 태스크 정보를 활용하여 새로운 태스크에 적용
- 예를 들어, 의미론적 분할을 학습한 모델이 객체 분할 태스크에도 쉽게 적용될 수 있음
벤치마크 성능 비교
DICEPTION은 여러 벤치마크에서 기존 태스크별 전용 모델(SAM-vit-h, DepthAnything 등)과 비교하여 동등하거나 뛰어난 성능을 보였습니다.
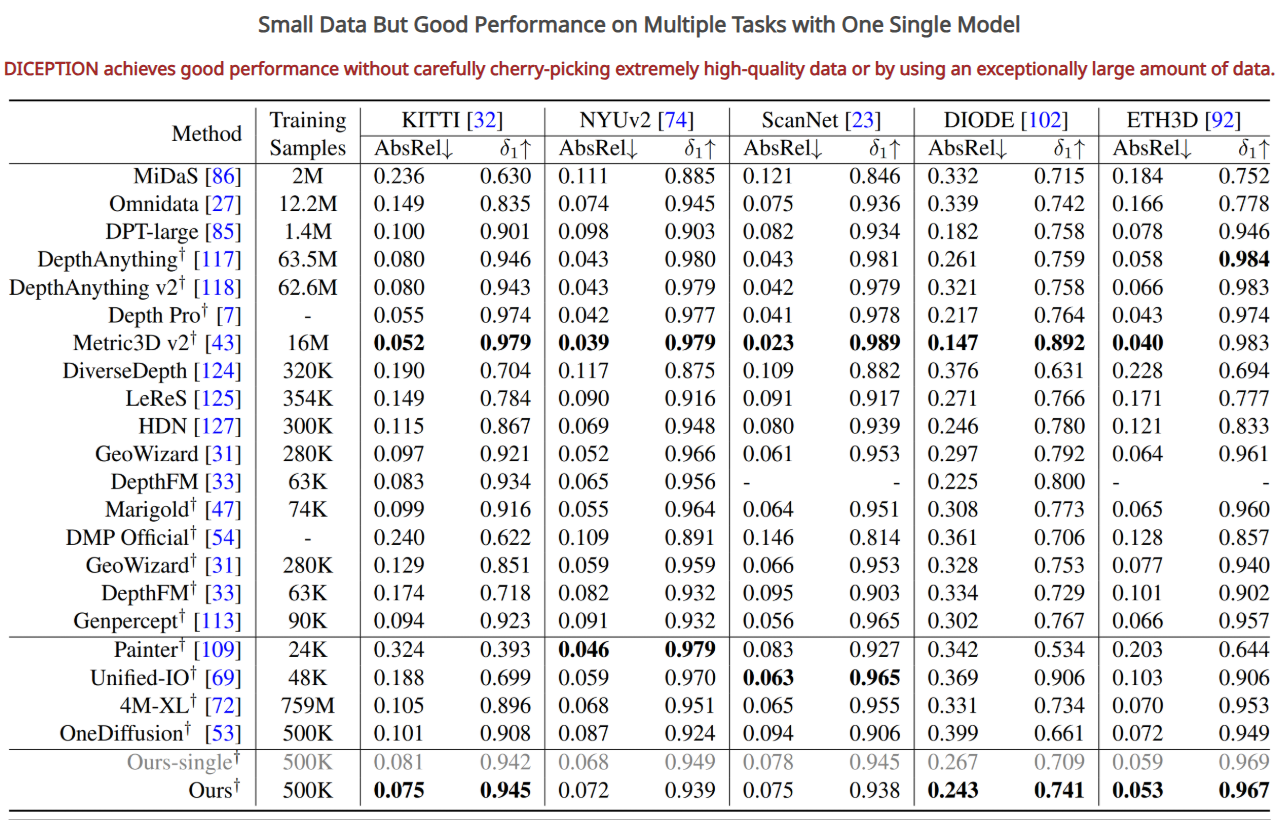
깊이 추정(Depth Estimation) 성능 비교
| 모델 | KITTI(↓) | NYUv2(↓) | ScanNet(↓) | DIODE(↓) | ETH3D(↓) |
|---|---|---|---|---|---|
| MiDaS | 0.236 | 0.111 | 0.121 | 0.332 | 0.184 |
| DepthAnything | 0.080 | 0.043 | 0.043 | 0.261 | 0.058 |
| DICEPTION | 0.075 | 0.072 | 0.075 | 0.243 | 0.053 |
DepthAnything 대비 유사한 성능을 유지하면서도 학습 데이터는 훨씬 적게 사용.
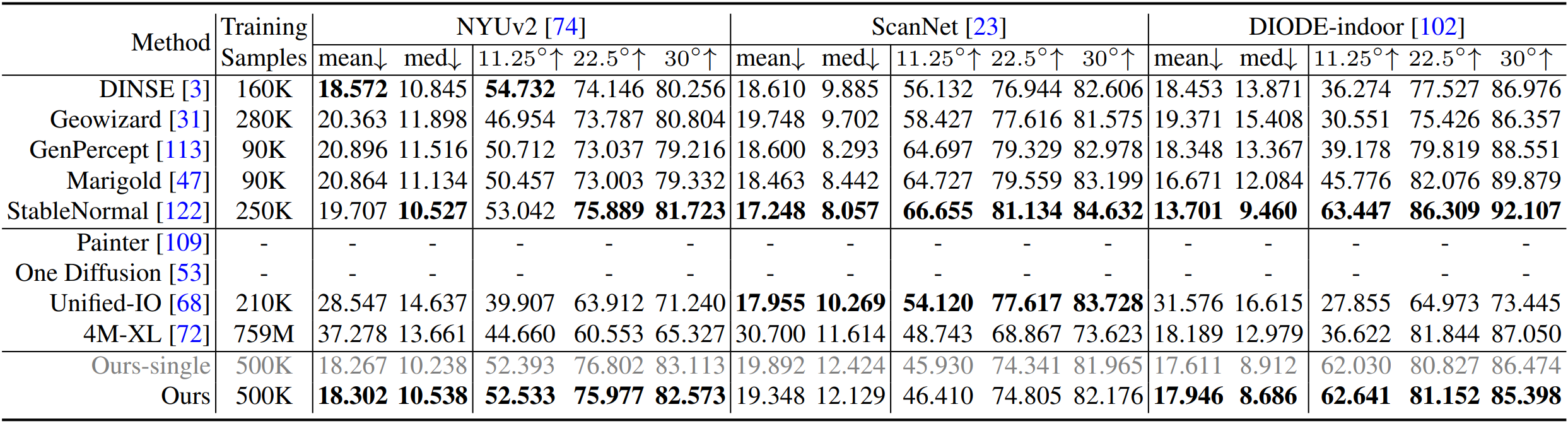
표면 법선(Surface Normal) 추정 성능 비교
| 모델 | NYUv2 (↓) | ScanNet (↓) | DIODE-indoor (↓) |
|---|---|---|---|
| StableNormal | 19.707 | 17.248 | 13.701 |
| DICEPTION | 18.302 | 19.348 | 17.946 |
표면 법선 추정에서도 기존 SOTA 모델들과 유사한 성능을 유지.
객체 분할(Entity Segmentation) 성능 비교
| 모델 | AR-small (↑) | AR-medium (↑) | AR-large (↑) |
|---|---|---|---|
| EntityV2 | 0.313 | 0.551 | 0.683 |
| DICEPTION | 0.121 | 0.439 | 0.637 |
객체 분할에서는 일부 성능 감소가 보이지만, 적은 데이터로도 학습 가능.
DICEPTION의 활용 분야

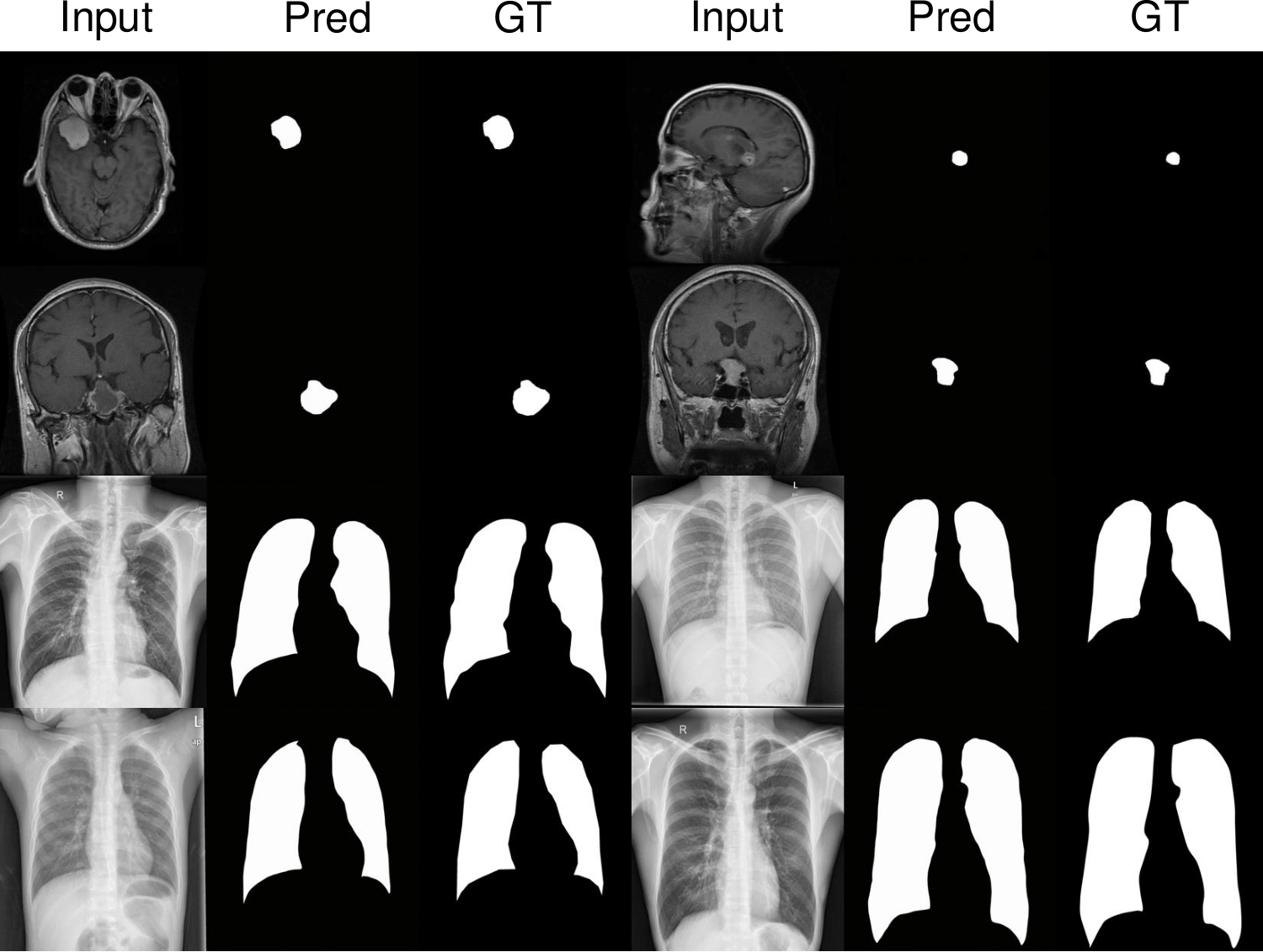
1. 로봇 비전 시스템
- 자율 주행 및 로봇 비전 시스템에서 다양한 시각 태스크 수행
- 실시간 객체 탐지 및 상호작용 가능
2. 의료 영상 분석
- X-ray, CT 스캔 등의 의료 영상에서 병변 감지 및 분할 수행
- 데이터가 적은 의료 영상에서도 Zero-shot 학습 가능
향후 발전 방향
- 작은 객체 감지 성능 개선: 작은 객체에 대한 분할 성능 향상 연구
- 실시간 모델 최적화: 모바일 및 엣지 디바이스에서의 실행 최적화
- 다중 태스크 학습 개선: 태스크 간 상호 학습을 통해 성능 향상
결론
DICEPTION은 다양한 시각 지각 태스크를 하나의 모델로 통합할 수 있는 강력한 AI 모델로,
기존의 태스크별 전용 모델 대비 적은 데이터와 연산 자원으로도 높은 성능을 제공합니다.
미래의 범용 시각 모델 연구에 중요한 기여를 할 것으로 기대됩니다.