Magma: 차세대 멀티모달 AI 에이전트
Magma: 차세대 멀티모달 AI 에이전트의 등장

🔥 멀티모달 AI의 혁신, Magma란 무엇인가?
오늘날 AI 기술은 텍스트와 이미지를 이해하는 수준을 넘어, 디지털 환경에서 조작을 수행하거나 물리적 환경에서 직접 행동할 수 있는 AI 에이전트로 발전하고 있습니다.
Microsoft Research에서 개발한 Magma는 이러한 차세대 멀티모달 AI 에이전트를 위한 새로운 패러다임을 제시하는 모델로, 디지털 및 물리적 환경에서 실제로 행동할 수 있는 능력을 갖춘 AI입니다.
📌 논문 링크: https://arxiv.org/abs/2502.13130
📌 프로젝트 페이지: https://microsoft.github.io/Magma
📌 GitHub 저장소: https://github.com/microsoft/Magma
🚀 1. Magma의 핵심 개요
Magma는 기존 Vision-Language (VL) 모델을 확장하여 “행동(Acting)”까지 수행할 수 있도록 설계된 최초의 멀티모달 기반 AI 모델입니다.
기존의 AI 모델들은 이미지/비디오를 이해하고 언어로 설명하는 것에 집중했다면,
Magma는 실제 환경에서 “행동”을 예측하고 수행할 수 있도록 설계되었습니다.
예를 들어,
- 웹 브라우저에서 버튼을 클릭하거나 입력 폼을 자동 완성할 수 있습니다.
- 로봇 시스템에서 팔을 움직여 물체를 조작할 수 있습니다.
- 게임 환경에서 캐릭터가 자율적으로 플레이할 수 있습니다.
🤖 AI 에이전트의 미래, Magma의 역할
기존 AI는 특정 작업(예: 이미지 캡셔닝, 자연어 처리)에서 뛰어난 성능을 보였지만, 환경을 직접 조작하는 능력은 부족했습니다. Magma는 이러한 한계를 극복하기 위해 개발된 모델로, 실제 환경에서 수행하는 AI 에이전트의 역할을 강화하는 데 중점을 두고 있습니다. 특히 “공간-시간적 추론 능력” 을 갖춘 것이 특징이며, 이는 단순히 특정 시점에서 데이터를 분석하는 것이 아니라, 과거 행동 데이터를 학습하여 미래의 행동을 예측하는 능력을 의미합니다.


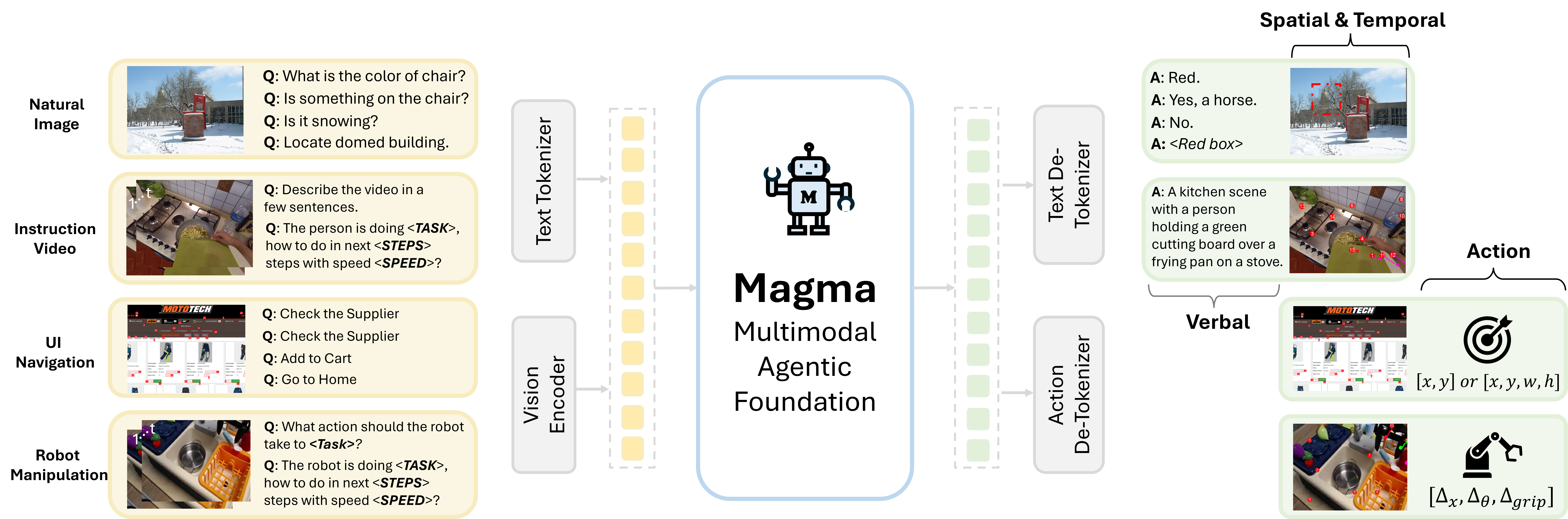
🏗️ 2. 내부 모델 아키텍처 (Transformer 기반)
Magma는 Transformer 기반 멀티모달 아키텍처를 사용하며,
다음과 같은 주요 컴포넌트로 구성됩니다.
🟢 비전(vision) 인코더
- ConvNeXt 기반 비전 모델 (CLIP-ConvNeXt-XXL)
- 이미지를 고차원 시각 토큰(Visual Token) 으로 변환
- 동영상 프레임을 시퀀스로 변환하여 시간적 정보를 유지
🔵 언어(Language) 모델
- LLaMA-3 기반 대형 언어 모델 (8.6B 파라미터)
- 텍스트 입력을 처리하고 의미적 맥락을 생성
- 시각 정보와 결합하여 멀티모달 표현을 생성
🟣 멀티모달 융합 (Cross-Attention Mechanism)
- 크로스-어텐션을 통해 이미지 & 텍스트를 통합
- Transformer 디코더는 텍스트, 좌표, 행동(Action) 토큰을 동시에 출력
- UI 조작, 로봇 동작, 공간 이해 등을 수행할 수 있도록 설계됨
🎯 3, Magma의 주요 기능
1️⃣ 멀티모달 이해 (Multimodal Understanding)
✅ 텍스트, 이미지, 비디오를 조합하여 복합적인 정보 처리
✅ 상황을 인식하고, 예측 및 분석 수행
✅ 텍스트와 비주얼 데이터의 상호작용을 분석하여 더욱 정확한 답변 생성
✅ 정확한 의도 파악을 위한 자연어 이해 (NLU) 기술 활용
예제 질문:
- “이 이미지에서 이상한 점은 무엇인가?”
- “이 버튼을 클릭하면 어떤 일이 발생하는가?”
- “이 장면에서 사람이 무엇을 하고 있는가?”
- “이 작업이 완료되기 위해 어떤 순서로 진행해야 하는가?”
2️⃣ 행동 예측 및 실행 (Multimodal Action Grounding & Planning)
✅ 디지털 환경(UI 자동화) 및 물리적 환경(로봇 조작)에서 실제 행동 수행
✅ 행동 계획을 수립하고, 환경 내에서 특정 액션을 실행
✅ 기존 UI 및 인터페이스와 원활하게 연동 가능
✅ 스마트 로봇과 연계하여 더 정교한 작업 수행 가능
예제:
- 웹 브라우저에서 로그인 버튼 클릭
- 모바일 앱에서 설정 페이지로 이동
- 로봇 팔을 이용하여 물건을 옮기기
- 도어를 자동으로 열고 닫기
- 물체를 특정 위치에 배치하고 이동시키기
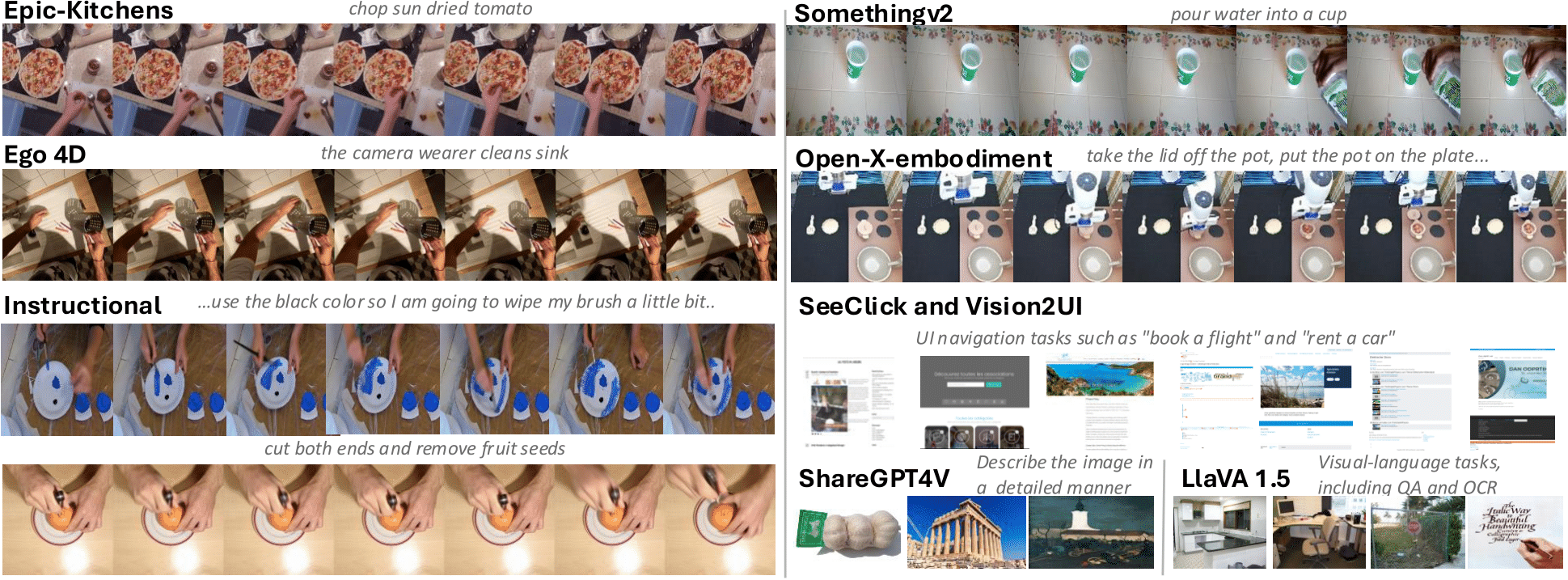
🔍 4. 학습 방법론 (지도 학습 + 강화 학습)
Magma는 대규모 멀티모달 데이터셋을 활용하여 학습됩니다.
📌 학습 데이터 규모
- 웹 UI 스크린샷: 270만 개
- 로봇 조작 시퀀스: 970K 에피소드 (약 940만 개 행동 샘플)
- 비디오 클립 기반 데이터: 약 2,500만 개
- GPT-4V, LLaVA 기반 멀티모달 데이터: 120만 개
📌 학습 방법
- 자기지도 학습(Self-Supervised Learning)
- 차세대 토큰 예측 방식(Next-Token Prediction)
- 강화 학습을 통한 행동 최적화 (Reinforcement Learning, RLHF)
🟢 SoM (Set-of-Mark) - 행동을 위한 시각적 마킹
- UI 내 클릭 가능한 요소(버튼, 입력창)를 바운딩 박스로 표시
- 로봇 조작 시, 조작할 수 있는 영역을 마킹
- 모델이 시각적 요소를 인식하고 올바른 액션을 수행하도록 학습
🔵 ToM (Trace-of-Mark) - 행동의 흐름을 학습
- 비디오에서 물체의 움직임을 추적하여 “행동 패턴”을 학습
- 이전 행동 데이터를 학습하여 “미래 행동”을 예측 가능
- 시간의 흐름에 따른 이벤트 변화를 모델링하여 지속적인 학습 가능
📊 5. 벤치마크 성능 비교
1️⃣ UI 네비게이션 (Mind2Web & AITW 벤치마크)
| 모델 | Mind2Web (웹 UI) | AITW (모바일 UI) |
|---|---|---|
| GPT-4V + OmniParser | 57.7% | 59.3% |
| Magma-8B (Ours) | 67.3% | 67.3% |
2️⃣ 로봇 조작 (SimplerEnv & Google Robot 테스트)
| 모델 | Google Robot | Bridge |
|---|---|---|
| OpenVLA | 31.7% | 14.5% |
| Magma-8B (Ours) | 52.3% | 35.4% |
🛠️ 5. Magma의 실제 응용 사례
✅ UI 자동화 & 웹 브라우저 조작
- 웹사이트 내 버튼 클릭, 입력 폼 자동 완성, UI 내비게이션 수행
- RPA (로봇 프로세스 자동화) 및 소프트웨어 테스트 자동화 적용
✅ 로봇 조작 및 자율 시스템
- 스마트 가정 로봇, 물류 로봇, 공장 자동화 적용
- 영상 피드백을 통한 자율 행동 최적화
✅ 의료 영상 분석 & 진단
- AI 기반 의료 영상 내 종양 감지, 데이터 분석
- CT, MRI 영상 기반 맞춤형 진단 모델
✅ 게임 AI 및 가상 환경 적용
- AI 기반 자동 게임 플레이, 퍼즐 해결 자동화
- VR/AR 환경 내 스마트 AI 비서 구축
🔮 7. Magma의 미래 발전 방향
1️⃣ UI 자동화 정밀도 향상
- 버튼 클릭 시, 더 정확한 위치 지정
- 동적 웹 페이지에서도 안정적으로 동작
- 복잡한 UI 내에서도 정확한 요소 선택 가능하도록 향상
2️⃣ 로봇 조작 학습 강화
- 더 복잡한 작업(예: “요리하기”) 수행 가능하도록 학습
- 실시간 카메라 피드로 피드백 받아 조정
- 인간과의 상호작용을 통해 더 자연스러운 행동 구현
3️⃣ 강화 학습 기반의 지속적인 성능 개선
- AI가 스스로 학습하면서 환경 적응 능력 향상
- 새로운 도메인에서도 손쉽게 적용 가능하도록 범용성 강화
🎯 8. 결론
Magma는 멀티모달 AI 모델의 새로운 기준을 제시합니다.
✅ 이미지 & 텍스트 이해 + 행동 계획 & 실행
✅ 웹 UI, 로봇 조작, 의료 영상 분석, 게임 AI까지 광범위한 활용 가능
✅ 기존 GPT-4V, OpenVLA 대비 10~20% 성능 향상
📢 미래의 AI 에이전트는 더 스마트하고, 더 정밀하게 행동할 것입니다. Magma가 그 시작점이 될 것입니다! 🚀