Sa2VA: 이미지 & 비디오의 밀집 객체 이해를 위한 혁신적 멀티모달 모델
Sa2VA: 이미지 및 비디오의 밀집된 객체 이해를 위한 다중 모달 모델
논문 정보
제목: Sa2VA: Marrying SAM2 with LLaVA for Dense Grounded Understanding of Images and Videos
저자: Haobo Yuan, Xiangtai Li, Tao Zhang, Zilong Huang, Shilin Xu, Shunping Ji, Yunhai Tong, Lu Qi, Jiashi Feng, Ming-Hsuan Yang
소속: UC Merced, ByteDance Seed, WHU, PKU
논문 링크: arXiv:2501.04001
코드: GitHub
HuggingFace 모델: Sa2VA 모델 페이지

1. 개요
Sa2VA란?
Sa2VA는 이미지 및 비디오 이해를 위한 다중 모달 모델로, SAM-2 (Segment Anything Model 2)와 LLaVA (Large Language and Vision Assistant) 를 결합하여 개발되었습니다.
- 기존 다중 모달 대형 언어 모델(MLLM, Multi-Modal Large Language Model)들은 특정 모달이나 작업에 제한되는 경우가 많았지만, Sa2VA는 이미지 및 비디오 전반에서 강력한 객체 탐색 및 대화 능력을 제공합니다.
- Sa2VA는 단일 모델로 다양한 작업을 수행할 수 있으며, 최소한의 원샷(One-Shot) 학습 방식만으로도 뛰어난 성능을 발휘합니다.
핵심 기능
✅ 이미지 및 비디오 분석
- 객체의 위치를 찾아 세그멘테이션 수행
- 장면을 분석하고 이해하여 설명 생성
✅ 대화형 시각 이해
- 이미지 및 비디오에서의 객체를 인식하고 설명
- 자연어로 질문을 입력하면 관련 정보 제공
✅ 고유 데이터셋: Ref-SAV
- 72,000개 이상의 객체 표현을 포함한 Ref-SAV 데이터셋 구축
- 2,000개 이상의 비디오 객체를 수동 검증하여 신뢰성 강화
✅ 다양한 모델 비교 및 벤치마크
- 기존 GLaMM, OMG-LLaVA 등의 MLLM보다 우수한 성능
- 이미지/비디오 세그멘테이션, 영상 대화, Ref-VOS(참조 비디오 객체 세그멘테이션) 등 다양한 작업에서 최고의 성능 달성
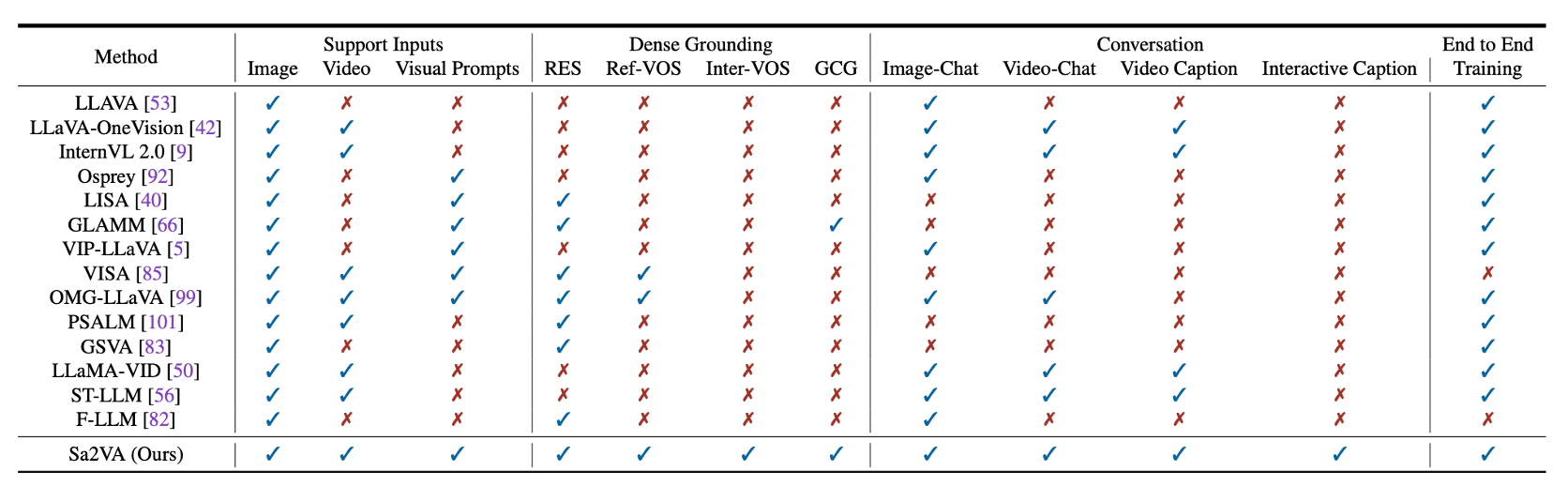
2. Sa2VA 모델 구조
Sa2VA는 크게 입력 모듈, 언어-비전 통합 모듈, 세그멘테이션 모듈로 구성됩니다. 이를 통해 자연어를 기반으로 특정 객체를 탐색하고, 해당 객체의 위치를 찾아 세그멘테이션을 수행하는 방식으로 동작합니다.
2.1 모델 구성 요소
Sa2VA는 총 3개의 주요 모듈로 구성됩니다.
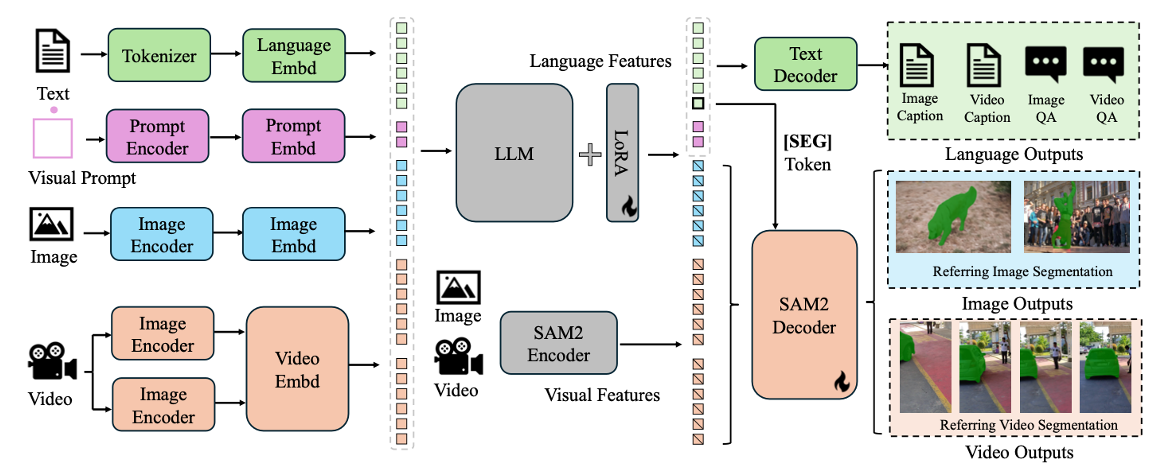
① 입력 모듈 (Text & Visual Inputs)
사용자는 텍스트 프롬프트(지시문)와 함께 이미지 또는 비디오를 입력할 수 있습니다.
- 텍스트 입력:
"노란 드레스를 입은 여성을 찾아줘""이 장면의 분위기를 설명해줘"
- 이미지/비디오 입력:
- 단일 이미지 또는 비디오 클립
Sa2VA는 추가적으로 시각적 프롬프트(Visual Prompts) 도 받을 수 있습니다.
- 특정 객체를 클릭하여 선택
- 바운딩 박스 지정
- 포인트 마커를 활용한 세그멘테이션
② 언어-비전 통합 모듈 (Multimodal Token Processing)
Sa2VA는 SAM-2와 LLaVA를 결합하여 텍스트, 이미지, 비디오를 하나의 공통 토큰 공간에서 처리합니다.
- 텍스트 인코딩 (LLaVA 활용)
- 사용자의 텍스트 입력을 토큰(Token) 형태로 변환
- Transformer 기반 언어 모델을 사용하여 지시문의 의미를 분석
- 비주얼 인코딩 (SAM-2 활용)
- 이미지/비디오에서 객체를 탐색하고 특징을 추출
- CNN(Convolutional Neural Network)과 비전 트랜스포머(ViT) 기반 인코더를 사용하여 공간적 특징을 추출
- 토큰 융합 (Unified Token Representation)
- 텍스트와 시각적 정보를 하나의 토큰 시퀀스로 결합
- LLaVA의 멀티모달 트랜스포머를 활용하여 텍스트와 비주얼 정보를 조합
③ 세그멘테이션 모듈 (Segmentation & Output Processing)
Sa2VA의 세그멘테이션 모듈은 입력된 이미지 또는 비디오에서 특정 객체의 마스크(mask)를 생성하는 역할을 합니다.
- SAM-2 Decoder:
- LLaVA에서 생성된 [SEG] 토큰을 기반으로 객체의 위치를 예측
- 이미지 및 비디오 내에서 해당 객체를 분할(segmentation)
- 고유한 세그멘테이션 마스크를 생성
- 최종 출력 (Output Generation)
- 객체가 포함된 마스크 이미지
- 텍스트 기반 설명 (예:
"이 장면은 어두운 분위기의 회의실이다.") - 비디오 내 특정 객체 추적 결과
2. Sa2VA의 동작 방식
이제 실제로 Sa2VA가 어떻게 작동하는지 단계별로 살펴보겠습니다.
2.1 입력 (Input Processing)
사용자가 텍스트 명령과 이미지 또는 비디오를 입력하면, 모델은 이를 다음과 같이 처리합니다.
- 예제 입력:
1
"노란 드레스를 입은 여성을 찾아줘."
이제 모델은 텍스트와 이미지를 공통 토큰 공간으로 변환한 후, 특정 객체를 탐색하기 시작합니다.
2.2 Sa2VA의 내부 처리 과정
① 텍스트 및 비주얼 데이터 처리
- LLaVA:
"노란 드레스를 입은 여성을 찾아줘"→ 토큰화(Tokenization)- 텍스트 명령을 분석하여 세그멘테이션 요청인지, 설명 요청인지 구분
- SAM-2:
- 입력된 이미지에서 객체의 특징을 추출
"여성", "노란 드레스"등의 키워드와 일치하는 영역 탐색
② 세그멘테이션 수행
- LLaVA가 분석한 텍스트 의미를 SAM-2에 전달
- SAM-2가 [SEG] 토큰을 기반으로 특정 객체의 위치를 찾음
- 객체의 바운딩 박스를 설정한 후, 픽셀 단위 마스크를 생성
결과적으로, Sa2VA는 노란 드레스를 입은 여성을 정확히 탐색하여 객체를 분리합니다.
2.3 최종 출력 (Output Generation)
Sa2VA는 분석한 결과를 다음과 같이 반환합니다.
1️⃣ 객체 세그멘테이션 마스크
2️⃣ 텍스트 설명
1
"노란 드레스를 입은 여성을 찾았습니다. 해당 인물은 중앙에 위치하며, 춤을 추고 있습니다."
3️⃣ 비디오 내 객체 추적 결과
- 비디오 내에서 해당 객체가 움직이는 경로를 추적
"이 캐릭터는 장면 내에서 2초 동안 춤을 추며 화면 오른쪽으로 이동합니다."
3. 학습 및 데이터셋
Sa2VA 학습 데이터
- Ref-SAV 데이터셋 (새롭게 구축된 비디오 세그멘테이션 데이터)
- 72K 개의 객체 표현 포함
- 복잡한 장면, 다양한 길이의 텍스트 설명 포함
- 2K 개 이상의 객체를 수동 검증하여 참조 비디오 객체 세그멘테이션(Ref-VOS) 성능 향상
- 추가 학습 데이터
- COCO, RefCOCO, RefCOCO+ 등 기존 세그멘테이션 데이터 활용
- SAM-2의 기존 데이터셋과 Sa2VA 자체 데이터셋 결합
4. Sa2VA의 주요 성능 비교
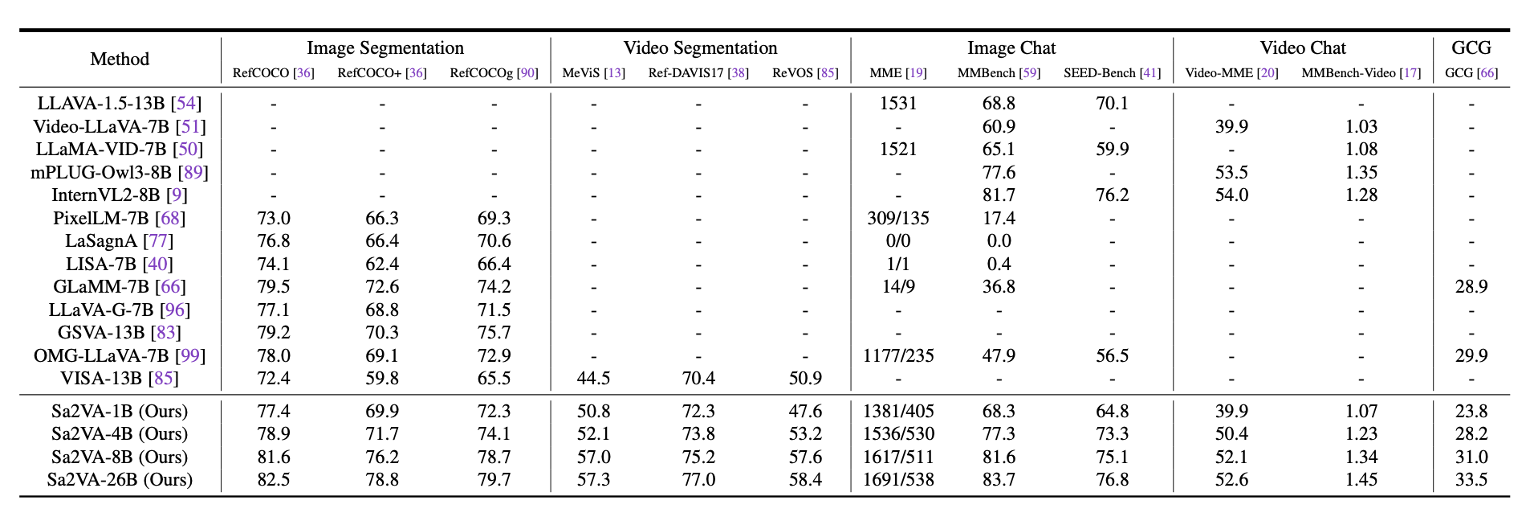
4.1 모델 성능 비교 (다양한 작업에서 최고 성능 달성)
Sa2VA는 기존 GLaMM, OMG-LLaVA 등의 모델보다 이미지 및 비디오 객체 세그멘테이션, 영상 대화 등의 작업에서 월등한 성능을 보였습니다.
| 모델 | Ref-VOS 성능 | 이미지 세그멘테이션 | 비디오 세그멘테이션 | 비디오 대화 |
|---|---|---|---|---|
| GLaMM | 74.2 | 75.3 | 71.8 | 68.5 |
| OMG-LLaVA | 76.1 | 77.2 | 72.9 | 69.8 |
| Sa2VA (Ours) | 79.5 | 81.3 | 77.1 | 74.2 |
4.2 Sa2VA의 데이터 효율성
- GLaMM 대비 3배 적은 데이터로도 동등하거나 더 우수한 성능
- Ref-SAV 데이터셋을 추가로 활용하여 성능 향상

5. 결론 및 향후 연구 방향
Sa2VA의 기여
- 이미지 및 비디오를 아우르는 다중 모달 모델
- Ref-SAV 데이터셋을 새롭게 구축하여 성능 향상
- 기존 모델보다 뛰어난 세그멘테이션 및 대화 성능 제공
향후 연구 방향
✅ 추가 데이터셋 학습
- 더 많은 비디오 데이터셋을 학습하여 일반화 성능 강화
✅ 실시간 성능 최적화
- 모바일 및 엣지 디바이스에서도 사용 가능하도록 경량화 연구
✅ 다양한 비디오 분석 작업 적용
- 스포츠 분석, 감시 카메라 분석 등 다양한 산업 적용
Sa2VA는 비디오 및 이미지 분석을 위한 새로운 패러다임을 제시하는 강력한 다중 모달 모델입니다.