Spark-TTS: 인공지능이 당신의 목소리를 만드는 방법

🎙️ Spark-TTS: AI가 목소리를 만드는 새로운 방법
“헤이 시리, 오늘 날씨 어때?” 부터 “네비게이션을 시작합니다” 까지… 우리는 매일 AI 목소리를 듣고 있습니다. 하지만 이 목소리들이 어떻게 만들어지는지 궁금하셨나요?
인공지능이 텍스트를 자연스러운 목소리로 바꾸는 기술, 즉 ‘텍스트-음성 변환(TTS)’은 최근 빠르게 발전하고 있습니다. 오늘 소개드릴 Spark-TTS는 이 분야의 최신 기술로, 기존 방식의 한계를 극복한 혁신적인 시스템입니다.
📱 일상에서 만나는 AI 음성 기술
여러분도 모르는 사이에 AI 음성 기술을 매일 사용하고 계실 겁니다:
- 스마트폰의 음성 비서
- 내비게이션 안내 음성
- 동영상 자동 더빙
- 오디오북
- 팟캐스트 자동 생성
이런 기술들이 계속 발전하면서 AI 목소리는 점점 더 자연스러워지고 있습니다. 하지만 지금까지의 기술은 몇 가지 중요한 한계가 있었죠.
🤔 기존 AI 음성 기술의 문제점
기존 TTS 시스템은 다음과 같은 문제가 있었습니다:
- 너무 복잡한 구조: 여러 단계의 처리 과정이 필요해 비효율적
- 제한된 음성 표현: 특정 목소리만 잘 표현하고 다양한 감정이나 억양 표현이 어려움
- 많은 계산 자원 필요: 고품질 음성을 만들기 위해 강력한 컴퓨터가 필요
쉽게 말해, 기존 방식은 마치 ‘여러 명의 통역사를 거쳐 메시지를 전달하는 것’처럼 복잡했습니다. 이제 Spark-TTS는 ‘직접 소통’하는 방식으로 이 문제를 해결합니다.
💡 Spark-TTS의 혁신: 음성을 만드는 새로운 방법
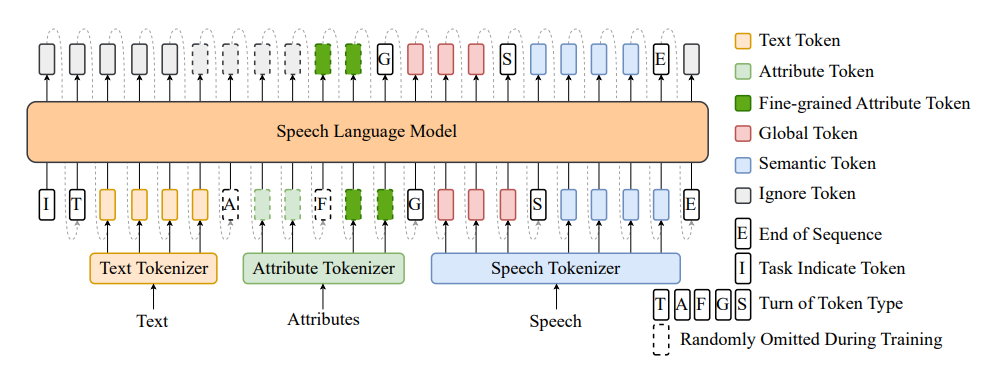
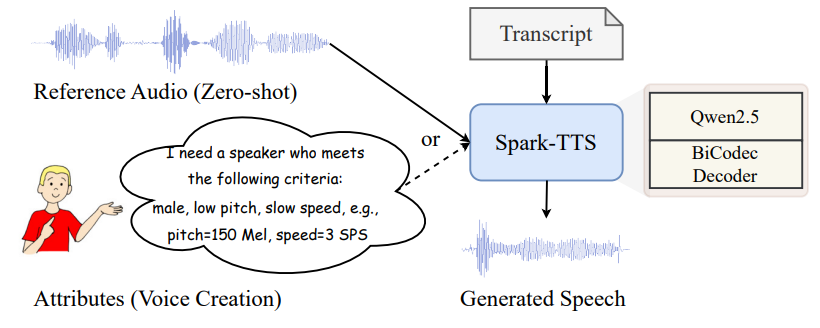
1. BiCodec: 음성을 더 스마트하게 이해하기
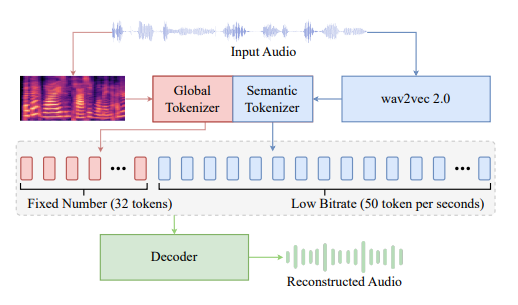
Spark-TTS의 가장 큰 혁신은 BiCodec이라는 새로운 기술입니다. 이것은 음성을 두 가지 핵심 요소로 나눠 처리합니다:
- 의미 토큰(Semantic Tokens): “무엇을 말하는지” 담당
- 텍스트의 내용과 언어적 특성을 저장
- 10배 더 효율적인 데이터 압축 방식 사용
- 전체 토큰(Global Tokens): “어떻게 말하는지” 담당
- 목소리 톤, 억양, 속도, 감정 등을 저장
- 화자의 고유한 특성을 보존
🔄 비유하자면: 글을 읽을 때 ‘내용’(무엇을 말하는지)과 ‘읽는 방식’(어떻게 말하는지)을 분리해서 생각하는 것과 같습니다.
2. 똑똑한 AI가 음성을 디자인: Qwen2.5 LLM & CoT
Spark-TTS는 Qwen2.5라는 강력한 AI 두뇌(대형 언어 모델)를 사용합니다. 이 AI는 단순히 텍스트를 읽는 것이 아니라, “어떻게 말하면 가장 자연스러울지” 스스로 생각하는 능력이 있습니다.
🧠 CoT(Chain-of-Thought) 방식은 AI가 단계적으로 생각하는 과정을 말합니다:
1
2
3
4
단계 1: 이 문장은 질문인가, 감탄인가, 명령인가?
단계 2: 어떤 감정을 담고 있는가? (기쁨, 슬픔, 중립적...)
단계 3: 어떤 속도와 톤이 적절한가?
단계 4: 최종 음성 생성
실제 사용 예시:
사용자: “여성 목소리로, 흥분된 톤으로, 빠르게 말해줘”
이전 기술: 참조 음성이 없으면 어려움 😕
Spark-TTS: 지시에 맞게 완전히 새로운 음성 생성 가능! 😃
3. VoxBox: 10만 시간의 목소리 데이터
AI는 배우는 만큼 똑똑해집니다. Spark-TTS는 VoxBox라는 거대한 음성 데이터셋으로 학습했습니다:
- 100,000시간 분량의 다양한 목소리 데이터
- 남녀노소 다양한 화자의 목소리 포함
- 감정, 억양, 속도 등 다양한 말하기 스타일 포함
- 완전 오픈소스로 누구나 사용 가능
이 방대한 데이터 덕분에 Spark-TTS는 마치 수만 명의 성우를 고용한 것 같은 다양한 목소리를 만들어낼 수 있습니다.
음성 복제 추론 구조

생성 컨트롤 추론 구조

📊 성능은 얼마나 좋을까?
효율성 측면: 적은 데이터로 더 좋은 음질
| 모델 | 데이터 사용량 | 음질 점수 |
|---|---|---|
| 기존 모델 | 🔴 많음 | ⭐⭐⭐ |
| Spark-TTS | 🟢 10배 적음 | ⭐⭐⭐⭐⭐ |
음성 제어 정확도: 원하는 목소리 만들기
Spark-TTS는 99.77% 의 정확도로 성별 특성을 제어할 수 있으며, 피치와 속도도 정밀하게 조절 가능합니다.
다국어 지원: 세계 여러 언어 자연스럽게
| 언어 | 발음 정확도 | 자연스러움 |
|---|---|---|
| 영어 | 🟢 매우 높음 | 🟢 매우 자연스러움 |
| 중국어 | 🟢 매우 높음 | 🟢 매우 자연스러움 |
| 한국어 | 🟡 높음 | 🟡 자연스러움 |
🚀 Spark-TTS로 가능한 미래
이 기술이 가져올 미래의 모습을 상상해볼까요?
- 개인화된 AI 비서: 여러분이 원하는 목소리와 말투로 정확히 대화하는 AI
- 실시간 번역 및 더빙: 외국어 영상이나 통화를 자연스럽게 실시간 번역
- 접근성 향상: 시각장애인을 위한 더 자연스러운 스크린 리더
- 콘텐츠 제작 혁신: 팟캐스트나 오디오북을 다양한 목소리로 쉽게 제작
⚡ 시연 영상: 직접 들어보세요!
아래 링크에서 Spark-TTS의 다양한 음성 샘플을 들어볼 수 있습니다:
🔗 Demo Page: https://sparkaudio.github.io/spark-tts/
🔮 앞으로의 과제
물론 Spark-TTS도 완벽하지는 않습니다. 개발팀이 앞으로 개선하려는 부분은:
- 화자 특성 더 정확히 복제하기: 특정 목소리를 더 정확히 모방
- 안정성 향상: 항상 일관된 품질의 음성 생성
- 더 적은 컴퓨팅 파워로 작동: 모바일 기기에서도 원활히 작동
🔍 직접 사용해보기
Spark-TTS는 오픈소스 프로젝트로, 누구나 사용하고 개선에 참여할 수 있습니다:
🔗 Hugging Face Model: https://huggingface.co/SparkAudio/Spark-TTS-0.5B
🔗 Demo Page: https://sparkaudio.github.io/spark-tts/
🔗 논문 원문 (arXiv): https://arxiv.org/abs/2503.01710
💬 여러분의 생각은?
- Spark-TTS 같은 기술이 일상에서 어떻게 활용되면 좋을까요?
- AI 음성 기술의 발전이 가져올 긍정적/부정적 영향은 무엇일까요?
- 여러분이 이 기술로 만들고 싶은 것이 있다면?
댓글로 여러분의 생각을 공유해주세요! 🗣️