UniTok: 이미지 생성과 이해를 동시에 수행하는 새로운 AI 토크나이저
UniTok: 이미지 생성과 이해를 하나로 통합한 혁신적 토크나이저
🔍 UniTok이란?

기존 이미지 기반 AI 모델들은 이미지 생성(generation)과 이미지 이해(understanding)를 별도로 처리해야 했습니다.
- 이미지 생성 모델 (e.g., VQVAE, SD-VAE) → 이미지를 세밀하게 생성하지만 의미적 이해가 부족
- 이미지 이해 모델 (e.g., CLIP, SigLIP) → 이미지를 분석할 수 있지만 생성 능력이 없음
UniTok은 이러한 한계를 극복하여 하나의 모델로 이미지 생성과 이해를 동시에 수행할 수 있도록 설계되었습니다.
- 이미지 생성 & 이해 통합: 기존 모델들이 개별적으로 수행하던 두 작업을 하나의 모델에서 해결
- Multi-Codebook Quantization 도입: 기존 토크나이저의 표현력 한계를 극복
- 통합 MLLM(Unified MLLM)과 결합 가능: 비전-언어 모델과 쉽게 통합되어 멀티모달 성능 강화
UniTok은 기존 토크나이저(tokenizer)들이 갖고 있던 학습 속도 저하, 성능 한계, 훈련 불안정성 문제를 해결하는 획기적인 솔루션입니다.
⚙️ UniTok의 핵심 기술
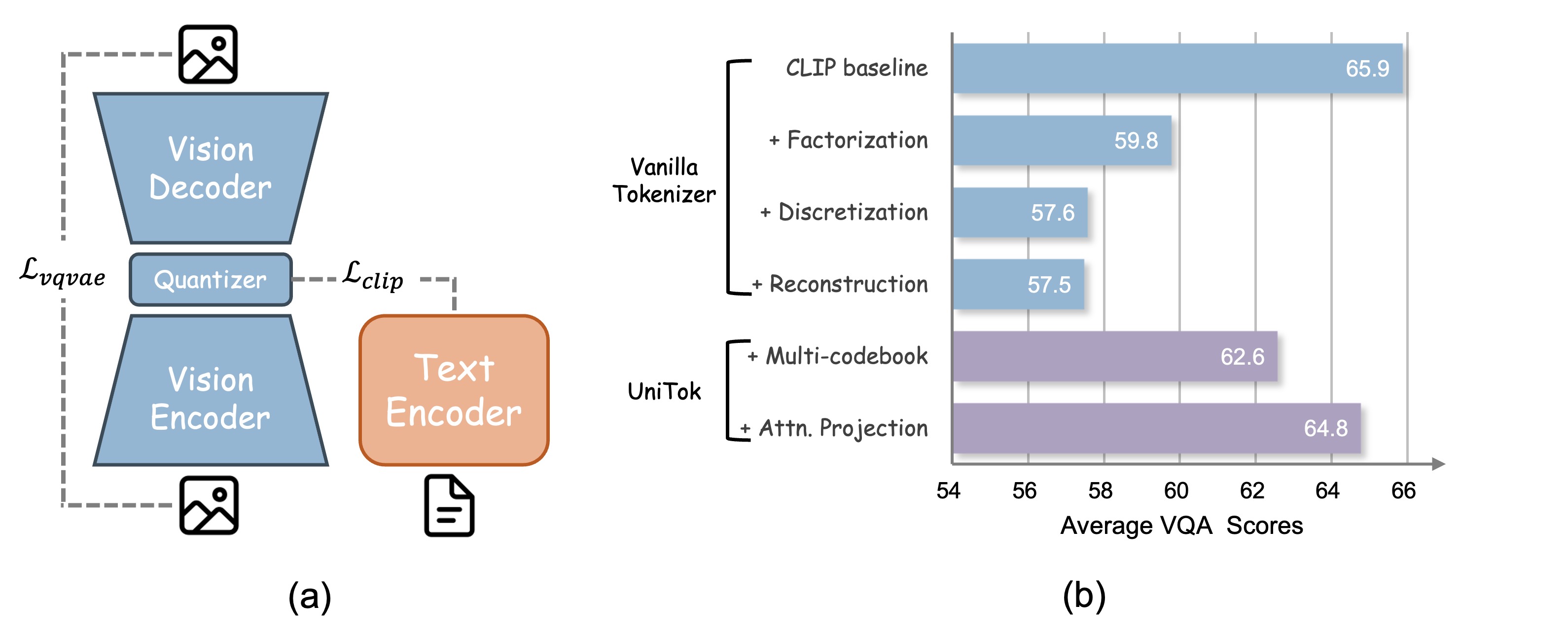
1️⃣ 기존 토크나이저의 한계
기존의 이미지 토크나이저들은 주로 다음 두 가지 방식으로 동작했습니다.
| 방법 | 특징 | 주요 문제점 |
|---|---|---|
| VQVAE 기반 생성 모델 | 이미지를 압축하여 토큰화 후 복원 | 의미적 이해 부족, 재구성 오류 가능 |
| CLIP 기반 이해 모델 | 이미지와 텍스트 간의 정합성 학습 | 생성 능력이 없음 |
하지만 생성과 이해를 동시에 수행해야 하는 MLLM(멀티모달 대형 언어 모델)이 발전하면서, 이 두 가지 방식을 하나로 통합할 필요성이 대두되었습니다.
이전 연구들은 이를 해결하기 위해 CLIP의 이미지 표현을 VQVAE 방식과 결합하는 전략을 시도했지만,
- 학습 속도가 느리고, 수렴이 어려우며, 최적의 성능을 내지 못하는 문제가 있었습니다.
- 이 문제는 단순한 학습 목표 충돌(conflict)이 아니라, 토큰 표현력의 한계(quantization bottleneck) 때문이라는 것이 UniTok 연구에서 밝혀졌습니다.
2️⃣ UniTok의 핵심 기술: Multi-Codebook Quantization(MCQ)
UniTok의 가장 중요한 기술적 혁신은 Multi-Codebook Quantization (MCQ)입니다.
✅ 기존 문제: 단일 코드북(One Codebook)의 한계
VQVAE 기반 방식은 하나의 코드북(codebook)을 사용하여 이미지를 압축하고 토큰화합니다.
하지만,
- 토큰 표현력이 낮아 세밀한 이미지 정보를 제대로 보존하지 못함
- 코드북 크기를 무작정 키우면 학습이 불안정해지고, 토큰 활용도가 낮아지는 문제가 발생
💡 UniTok의 솔루션: Multi-Codebook Quantization (MCQ)
MCQ는 기존의 단일 코드북을 여러 개의 독립적인 코드북으로 나누어 활용하는 방식입니다.
| 기존 방식 (VQVAE) | UniTok의 MCQ 방식 |
|---|---|
| 하나의 거대한 코드북 사용 | 여러 개의 작은 코드북으로 나눔 |
| 코드북이 커질수록 학습 불안정 | 코드북을 분할하여 학습 안정성 유지 |
| 표현력이 제한적 | 표현 공간을 확장하여 고품질 이미지 생성 & 이해 가능 |
MCQ 방식의 장점은 다음과 같습니다.
✅ 여러 개의 작은 코드북 사용 → 토큰 표현력이 증가하여 더 정밀한 정보 저장 가능
✅ 훈련 안정성 증가 → 코드북 크기를 무작정 키우는 방식보다 안정적인 학습 가능
✅ 연산 효율성 향상 → 기존 방식보다 적은 연산으로 더 좋은 품질의 이미지 생성
🔍 UniTok의 동작 원리
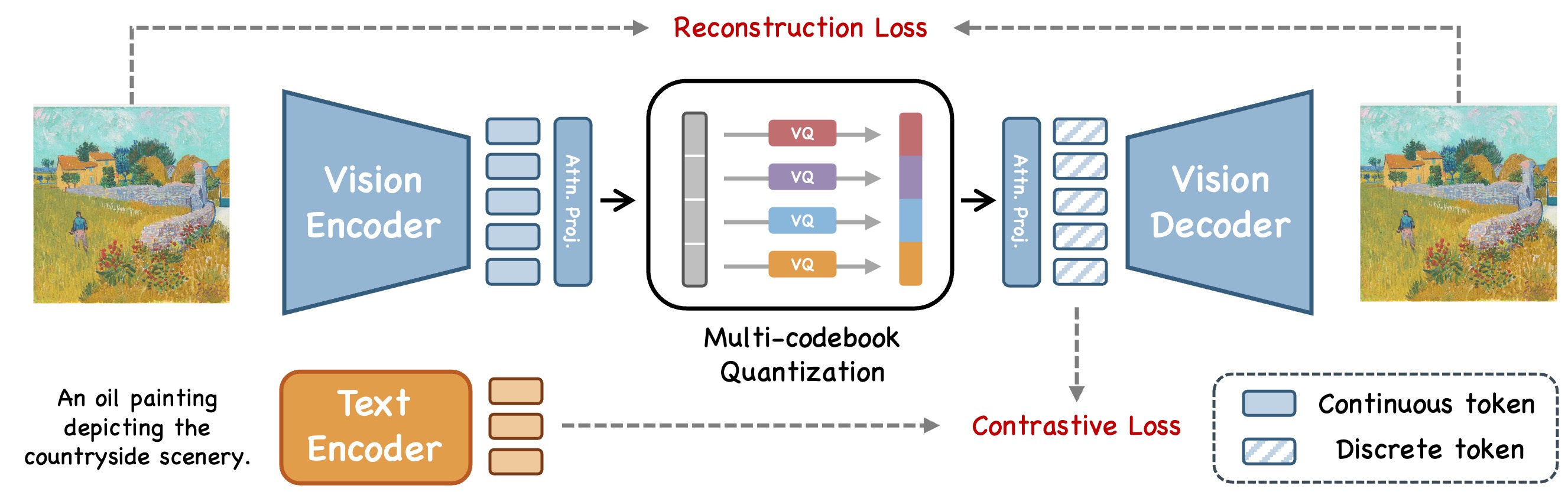
UniTok의 동작 과정은 크게 이미지 토큰화(Image Tokenization), 멀티모달 학습(Multi-Modal Learning), 토큰 기반 생성(Token-based Generation) 세 단계로 나뉩니다.
1️⃣ 이미지 토큰화 과정
UniTok은 이미지를 고차원 벡터 공간에서 압축하여 토큰(sequence of discrete codes)으로 변환합니다. 이 과정에서 VQVAE 방식의 한계를 극복하기 위해 Multi-Codebook Quantization(MCQ) 방식을 사용합니다.
✅ 단계별 과정
- 이미지 입력 (Input Image)
- 원본 이미지를 받아서 CNN 및 Transformer 인코더를 통해 특징 맵(feature map) 으로 변환
- 토큰 생성 (Tokenization with MCQ)
- 특징 맵을 여러 개의 코드북(codebook)을 사용하여 압축된 토큰 시퀀스로 변환
- 기존의 단일 코드북 방식(VQVAE)보다 더 정밀하고 압축 효율이 높은 표현 가능
- 토큰 출력 (Discrete Tokens Output)
- 최종적으로 생성된 토큰들은 MLLM(멀티모달 AI 모델) 에서 활용될 수 있음
2️⃣ 멀티모달 학습 (Multi-Modal Learning)
UniTok은 이미지 토큰과 텍스트 토큰을 결합하여 학습합니다. 이를 통해 LLaVA, GPT-4V 같은 멀티모달 AI 모델이 더 정밀한 비전-언어 학습을 수행할 수 있도록 지원합니다.
✅ 단계별 과정
- 텍스트-이미지 정합 학습 (Contrastive Learning)
- UniTok이 생성한 이미지 토큰과 관련된 텍스트를 CLIP-style contrastive loss를 통해 매칭
- 이미지와 텍스트가 의미적으로 연결되도록 학습
- 토큰-기반 이해 학습 (Token-based Understanding)
- LLM(예: GPT 계열)에서 UniTok의 이미지 토큰을 이해하도록 학습
- 이미지 설명, 질문응답(VQA), 객체 탐지 등 다양한 태스크 가능
3️⃣ 토큰 기반 생성 (Token-based Generation)
UniTok의 토큰들은 단순한 이미지 표현을 넘어 생성 모델에서도 활용 가능합니다.
기존 VQVAE 기반 생성 모델보다 더 정교한 이미지 생성이 가능합니다.
✅ 단계별 과정
- 토큰 입력 (Token Input)
- 기존 이미지에서 추출된 토큰을 기반으로 새로운 이미지를 생성
- LLaMA, GPT-4 등 대형 언어 모델(LLM)과 결합 가능
- 이미지 디코딩 (Image Decoding)
- 토큰 시퀀스를 다시 고해상도 이미지로 변환
- MCQ 기반의 고품질 재구성 가능
- 최종 출력 (Final Output)
- 원본 이미지와 거의 동일한 품질의 생성 가능
- 기존 VQVAE 방식보다 더 정밀한 이미지 생성 가능
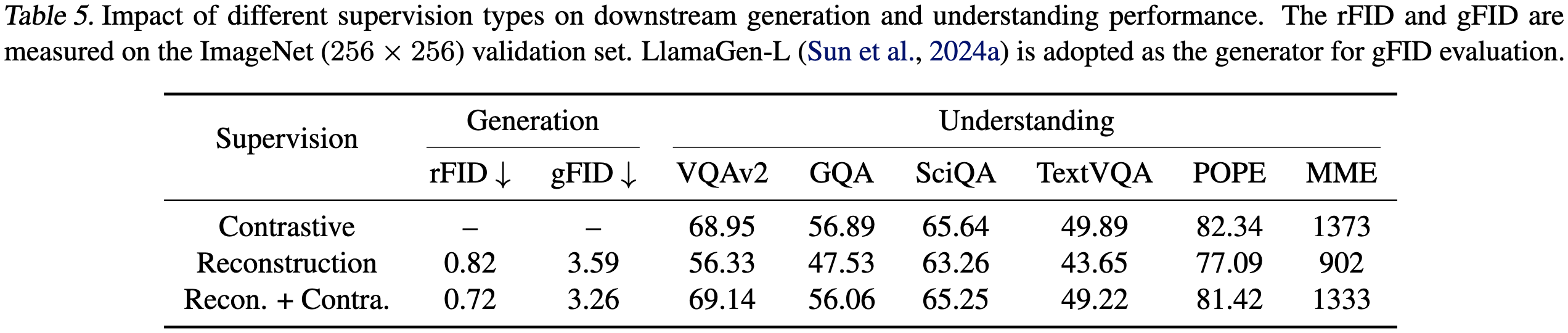
🚀 UniTok의 성능 비교
UniTok은 기존 토크나이저들보다 높은 성능을 자랑합니다.
✅ 이미지 생성 품질 (rFID ↓): 기존 VQVAE 기반 모델보다 높은 품질의 이미지 생성 가능
✅ 이미지 이해 성능 (zero-shot accuracy ↑): 기존 CLIP 기반 모델과 비교해도 우수한 이해 능력 제공
| 모델 | 이미지 생성 성능 (rFID ↓) | 이미지 이해 성능 (Zero-shot Accuracy ↑) |
|---|---|---|
| VQ-GAN | 4.98 | - |
| RQ-VAE | 1.30 | - |
| VAR | 0.90 | - |
| CLIP | - | 76.2 |
| SigLIP | - | 80.5 |
| ViTamin | - | 81.2 |
| UniTok | 0.38 | 78.6 |

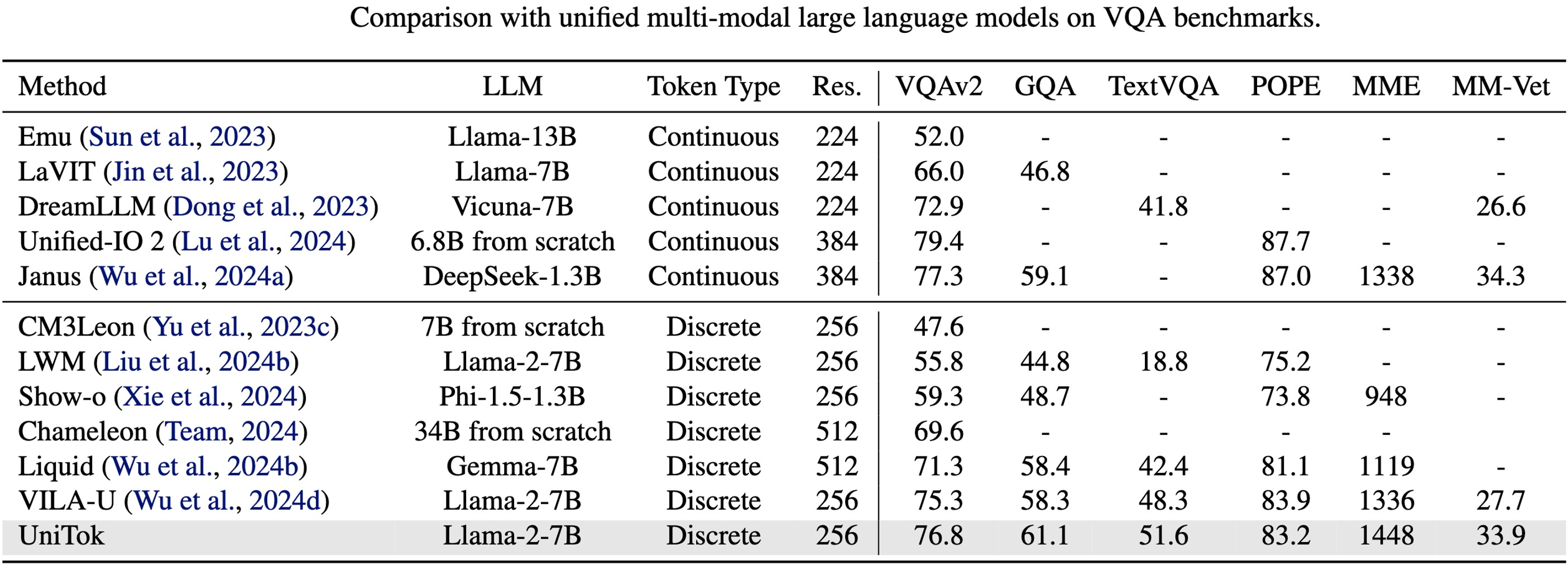
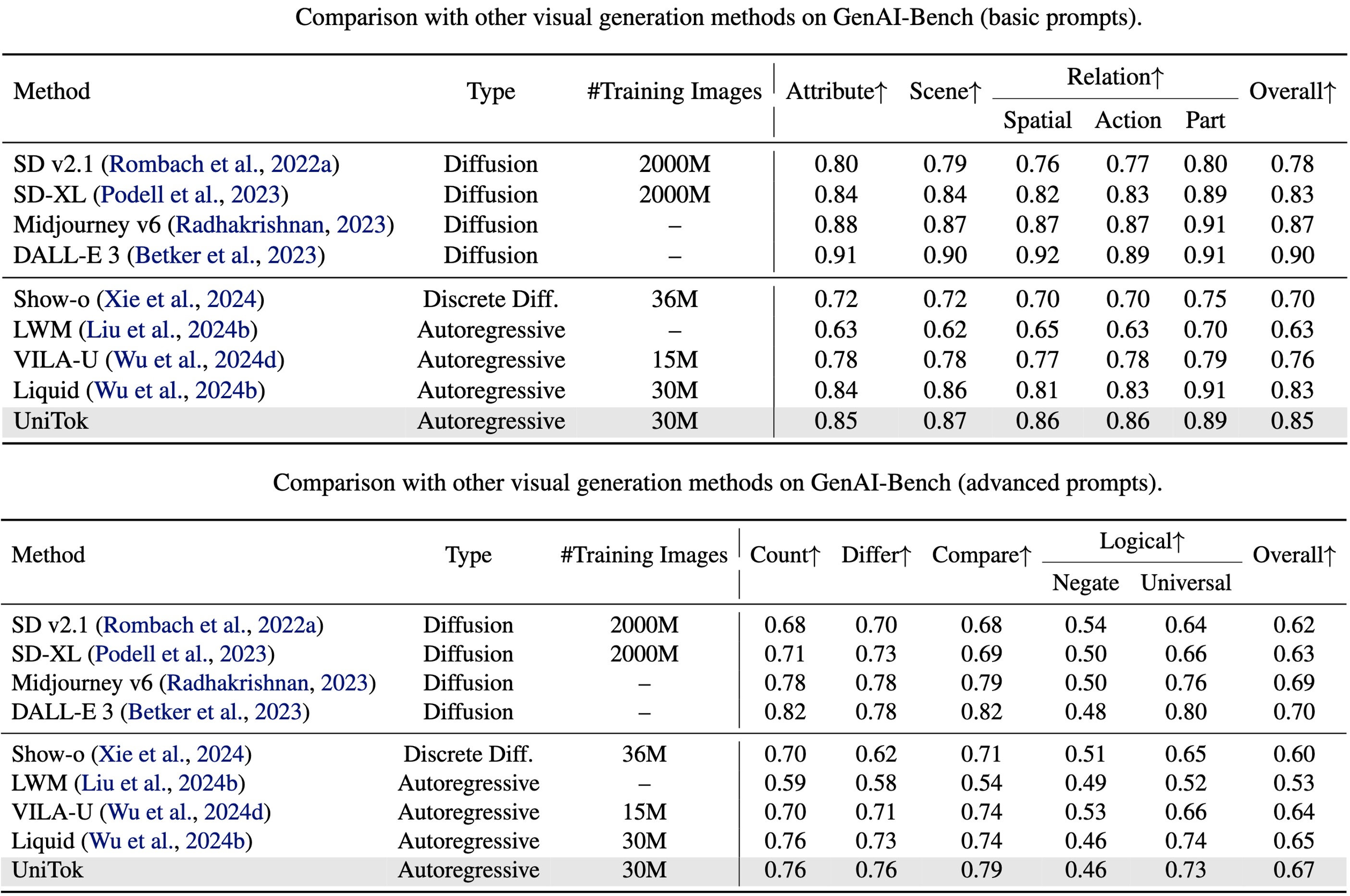
💡 UniTok의 활용 가능성
UniTok은 멀티모달 AI의 핵심 구성 요소로서 다양한 분야에서 활용될 수 있습니다.
✔️ 멀티모달 AI 모델 개발 (예: 챗봇, 영상 분석, 로봇 비전)
✔️ 고품질 이미지 생성 모델 (예: Stable Diffusion, DALL-E와 같은 모델 개선)
✔️ 실시간 영상 분석 및 객체 인식 (예: 자율주행, 보안, 의료 영상 분석)
📌 결론
UniTok은 이미지 생성과 이해를 동시에 수행할 수 있는 최초의 통합 토크나이저 중 하나입니다. MCQ 기반으로 성능 향상과 학습 안정성을 모두 잡은 혁신적인 접근 방식이며, 앞으로 멀티모달 AI의 발전에 중요한 역할을 할 것으로 기대됩니다.