VideoLLaMA3 훑어보기
VideoLLaMA 3: 최첨단 멀티모달 비디오 이해 모델
🔍 개요
📄 논문: https://arxiv.org/abs/2501.13106
🛠️ GitHub: https://github.com/DAMO-NLP-SG/VideoLLaMA3
VideoLLaMA 3는 이미지 및 비디오 이해를 위한 최신 멀티모달 기반 모델로,
시간적 특성을 반영한 비전 중심(vision-centric) 학습 패러다임과 프레임워크 디자인을 적용하여 강력한 성능을 제공합니다.

🎯 주요 특징
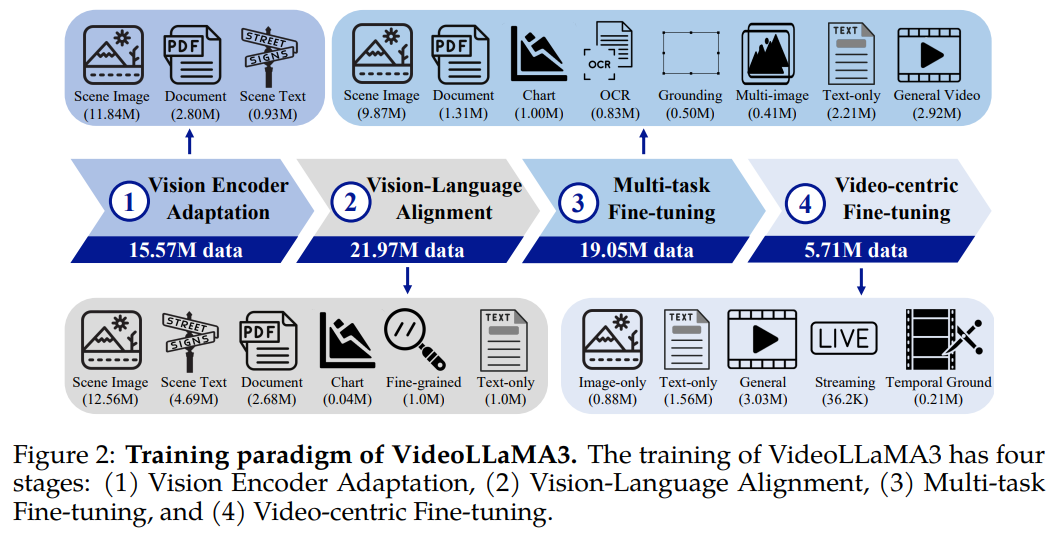
🔥 비전 중심(vision-centric) 학습 패러다임
기존의 비디오-텍스트 데이터셋은 품질이 낮거나 부족한 경우가 많음.
이를 해결하기 위해 고품질 이미지-텍스트 데이터 중심의 학습을 적용함.
📌 4단계 학습 과정
1️⃣ 비전 인코더 적응 (Vision Encoder Adaptation)
2️⃣ 비전-언어 정렬 (Vision-Language Alignment)
3️⃣ 멀티태스크 파인튜닝 (Multi-task Fine-tuning)
4️⃣ 비디오 중심 파인튜닝 (Video-centric Fine-tuning)
🎬 혁신적인 비디오 처리 기술
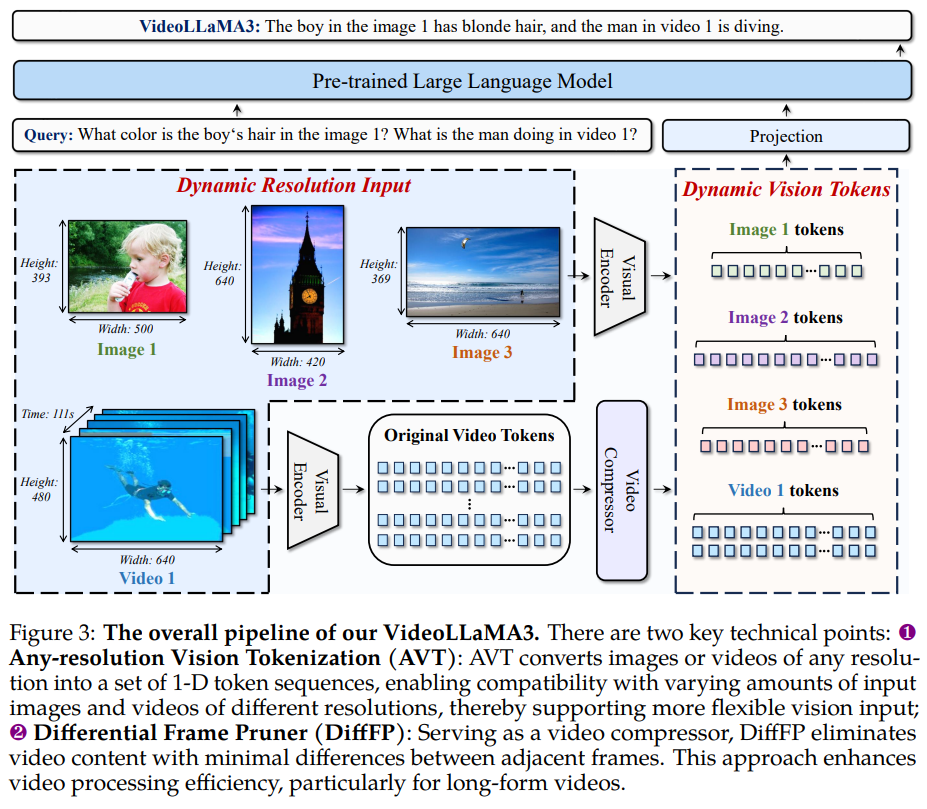
1️⃣ Any-resolution Vision Tokenization (AVT)
✔ 다양한 해상도 처리 가능
✔ 비디오 데이터의 고해상도 정보 보존

2️⃣ Differential Frame Pruner (DiffFP)
✔ 중복 프레임을 제거하여 연산량 감소
✔ 중요한 정보만 유지하여 효율적인 비디오 처리
3️⃣ 고품질 데이터셋 활용
- VL3-Syn7M 데이터셋 구축 (7백만 개의 고품질 이미지-텍스트 쌍)
- OCR 데이터, 차트 분석 데이터, 수학적 시각적 문제 해결 데이터 포함
4️⃣ 대규모 사전 학습
- OpenAI, Meta 등의 최신 연구 반영한 Qwen2.5 LLM 모델 기반
- 사전 훈련된 SigLIP 비전 인코더 개선
📊 성능 평가
🖼️ 이미지 이해 성능
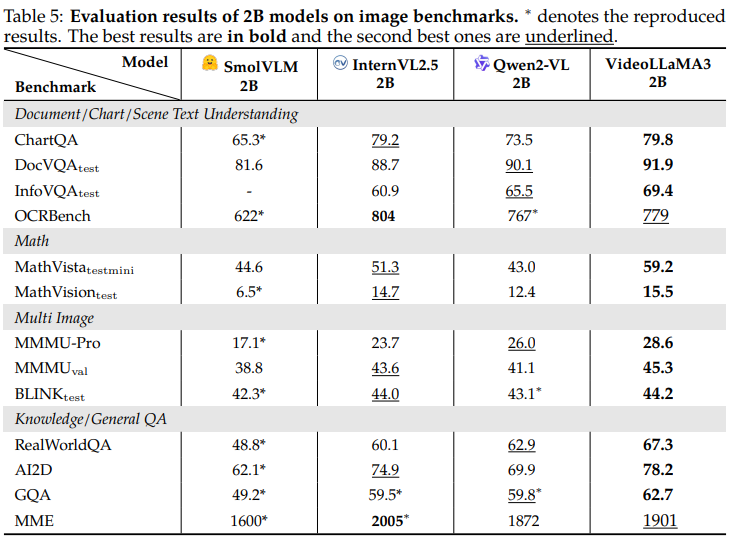
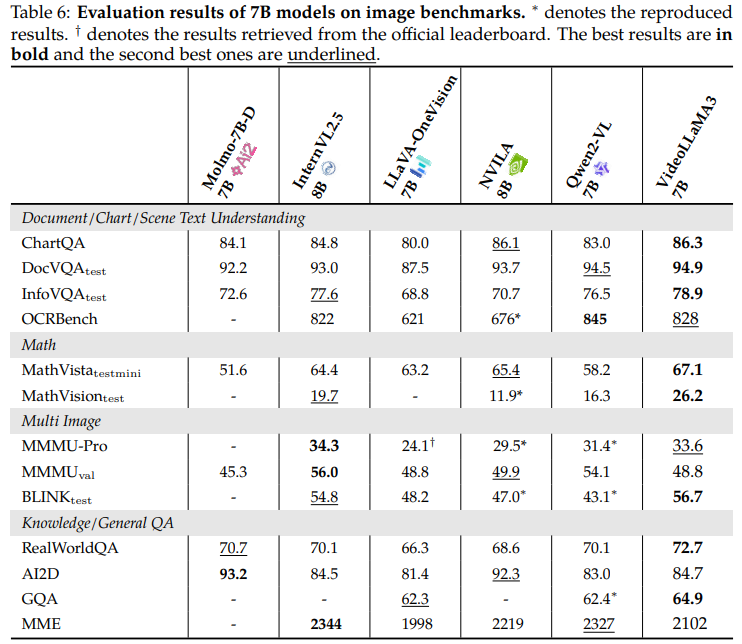
| 모델 | ChartQA | DocVQA | MathVista | MMMU-Pro | RealWorldQA |
|---|---|---|---|---|---|
| VideoLLaMA 3 (7B) | 86.3 | 94.9 | 67.1 | 33.6 | 72.7 |
| Qwen2-VL 7B | 83.0 | 94.5 | 58.2 | 31.4 | 70.1 |
| LLaVA-OneVision | 80.0 | 87.5 | 63.2 | 24.1 | 66.3 |
🎬 비디오 이해 성능
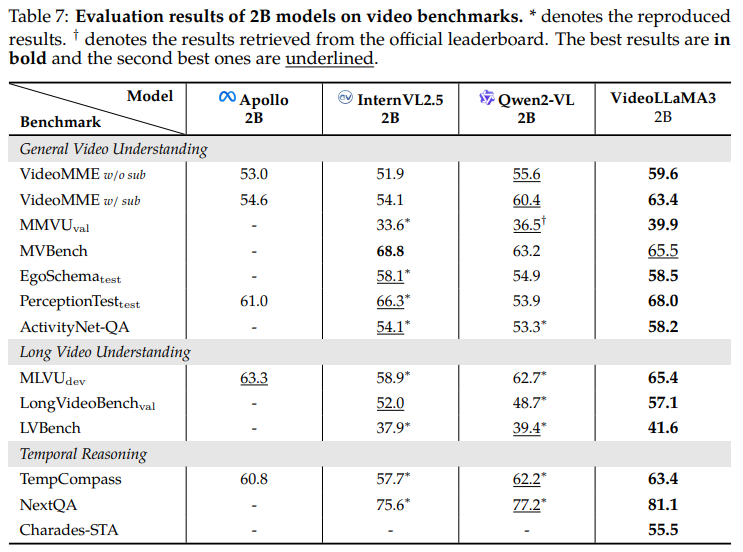
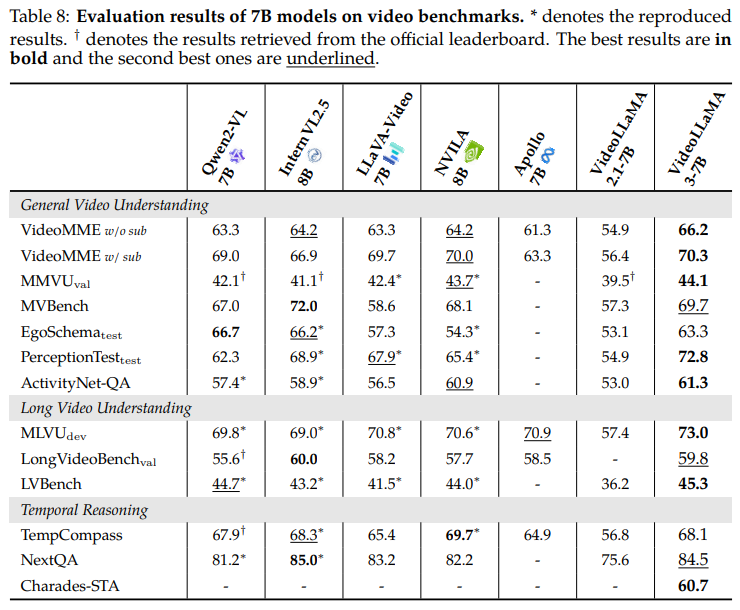
| 모델 | VideoMME | PerceptionTest | MLVU | TempCompass | NextQA |
|---|---|---|---|---|---|
| VideoLLaMA 3 (7B) | 66.2 | 72.8 | 73.0 | 68.1 | 84.5 |
| InternVL2.5 8B | 64.2 | 68.9 | 69.0 | 68.3 | 85.0 |
| Qwen2-VL 7B | 63.3 | 62.3 | 69.8 | 67.9 | 81.2 |
✅ 대부분의 벤치마크에서 SOTA 성능 달성!
🛠️ 설치 및 사용법
📌 기본 환경 설정
1
2
3
4
pip install torch==2.4.0 torchvision==0.17.0 --extra-index-url https://download.pytorch.org/whl/cu118
pip install flash-attn --no-build-isolation
pip install transformers==4.46.3 accelerate==1.0.1
pip install decord ffmpeg-python imageio opencv-python
📌 모델 다운로드
1
2
3
git clone https://github.com/DAMO-NLP-SG/VideoLLaMA3
cd VideoLLaMA3
pip install -r requirements.txt
📌 추론(Inference) 코드 예제
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
import torch
from transformers import AutoModelForCausalLM, AutoProcessor
device = "cuda:0"
model_path = "DAMO-NLP-SG/VideoLLaMA3-7B"
model = AutoModelForCausalLM.from_pretrained(
model_path, trust_remote_code=True, device_map={"": device},
torch_dtype=torch.bfloat16, attn_implementation="flash_attention_2",
)
processor = AutoProcessor.from_pretrained(model_path, trust_remote_code=True)
conversation = [
{"role": "system", "content": "You are a helpful assistant."},
{
"role": "user",
"content": [
{"type": "video", "video": {"video_path": "./assets/cat_and_chicken.mp4", "fps": 1, "max_frames": 180}},
{"type": "text", "text": "What is the cat doing?"}
]
},
]
inputs = processor(conversation=conversation, add_system_prompt=True, add_generation_prompt=True, return_tensors="pt")
inputs = {k: v.to(device) if isinstance(v, torch.Tensor) else v for k, v in inputs.items()}
output_ids = model.generate(**inputs, max_new_tokens=1024)
response = processor.batch_decode(output_ids, skip_special_tokens=True)[0].strip()
print(response)
🔍 활용 사례
🖼️ 차트 분석 (Chart Understanding)
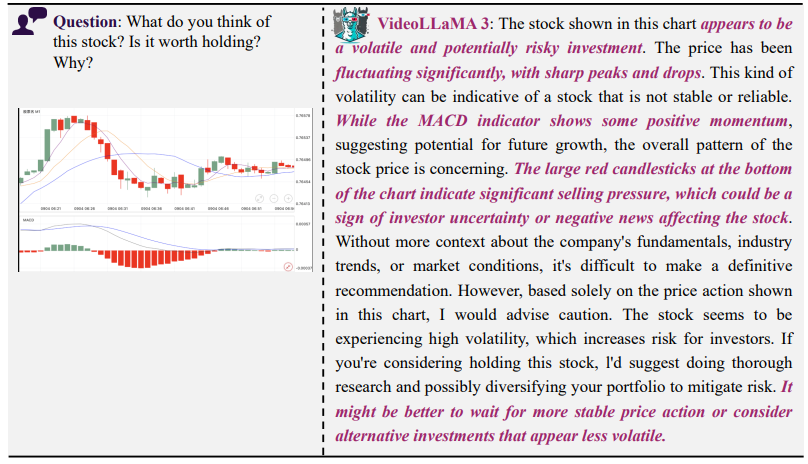
📌 질문: 이 주식은 보유할 가치가 있을까?
📌 VideoLLaMA 3의 답변: “해당 주식은 변동성이 크고 투자 위험이 높아 보입니다.”
📄 OCR 및 문서 이해 (Document Understanding)
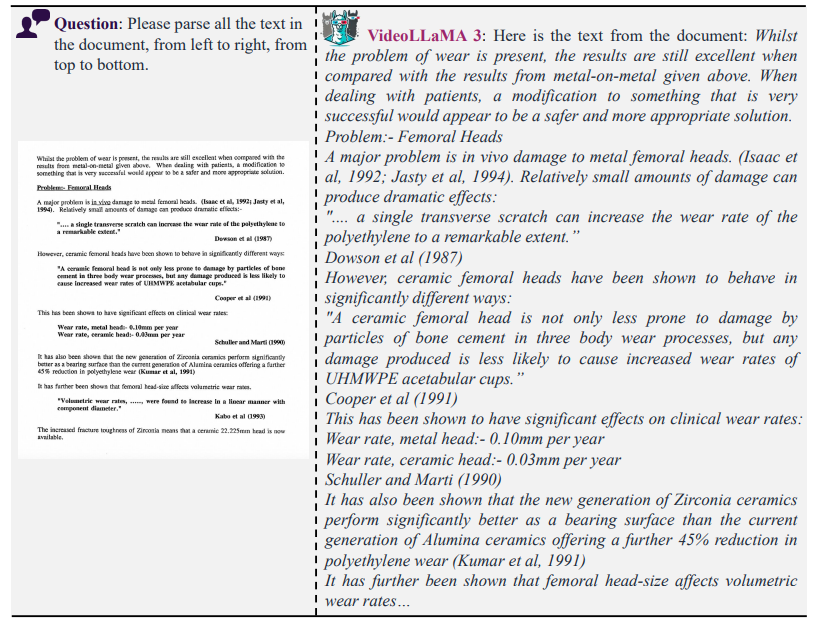
📌 질문: 문서의 내용을 요약해 주세요.
📌 VideoLLaMA 3의 답변: “문서에서 읽은 주요 내용은…”
🎬 비디오 캡션 생성 (Video Captioning)

📌 질문: 이 비디오의 내용을 설명해 주세요.
📌 VideoLLaMA 3의 답변: “이 비디오는 우주선이 궤도를 도는 장면으로 시작됩니다…”
🚀 결론
VideoLLaMA 3는 최신 멀티모달 AI 모델 중 최강의 성능을 제공하며, 특히 비디오 및 이미지 이해에서 강력한 성능을 발휘합니다.
✔ 비전 중심 학습 패러다임 적용
✔ SOTA 성능 달성 (최신 벤치마크 1위 기록)
✔ 비디오 캡션, OCR, 차트 분석, 문서 이해 등 다양한 활용 가능