YOLOE: 모든 객체를 실시간으로 탐지 & 분할하는 혁신 기술
YOLOE: 실시간으로 모든 객체를 감지하고 분할하는 혁신 기술

YOLOE는 기존 YOLO 모델의 한계를 뛰어넘어, 사전 정의된 카테고리에 구애받지 않고 다양한 오픈 프롬프트(텍스트, 비주얼, 프롬프트 없음)로 객체를 감지하고 분할하는 차세대 AI 모델입니다.
그렇다면, YOLOE는 어떻게 동작할까요?
💡 핵심 개념: YOLOE는 세 가지 기술(RepRTA, SAVPE, LRPC)을 통해 다양한 방식으로 객체를 감지하고 분할합니다.
이를 YOLO 기반의 최적화된 아키텍처 위에서 구현하여, 빠르고 정확한 성능을 유지할 수 있습니다.
YOLO의 한계를 넘다: YOLOE의 등장 🚀
기존 YOLO 모델은 빠르고 정확한 객체 탐지 성능 덕분에 자율주행, 보안, 로봇 비전 등 다양한 분야에서 활용되었습니다.
그러나 한 가지 문제점이 있었습니다.
사전 정의된 카테고리만 탐지할 수 있다!
이제 YOLOE는 이를 해결합니다.
✅ 텍스트 프롬프트로 원하는 객체만 탐지 가능
✅ 비주얼 프롬프트(이미지 예시) 기반 탐지 지원
✅ 프롬프트 없이도 자동으로 모든 객체 탐지 가능
✅ 기존 YOLO 모델보다 3× 빠른 학습, 1.4× 빠른 추론
YOLOE는 YOLO 아키텍처의 장점을 유지하면서도,
더 적은 연산으로 더 다양한 탐지 기능을 제공하는 차세대 AI 모델입니다.
🔍 YOLOE의 아키텍처
YOLOE의 전체적인 동작 방식은 기존 YOLO 모델을 기반으로 하되,
오픈 프롬프트 탐지를 위해 3가지 새로운 모듈을 추가하는 방식입니다.
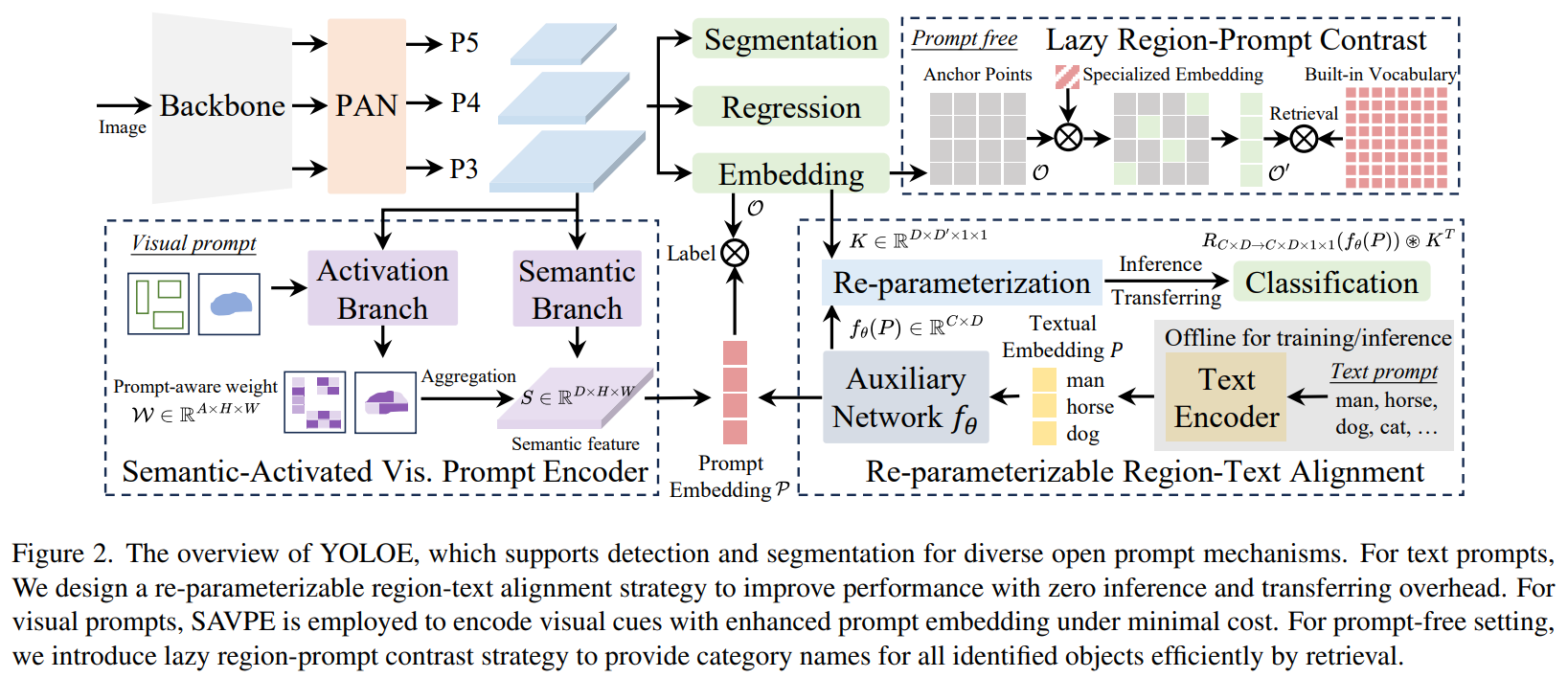
YOLOE의 주요 구성 요소
YOLOE는 기존 YOLO 모델과 유사한 구조를 가지면서도,
텍스트, 비주얼 프롬프트, 프롬프트 없이도 객체를 탐지할 수 있도록 설계되었습니다.
1️⃣ 백본(Backbone):
- 입력 이미지를 다중 스케일 특징(feature map)으로 변환
- YOLOv8과 동일한 아키텍처 사용 (하지만 프롬프트 처리를 위한 추가 기능 포함)
2️⃣ PAN(Feature Pyramid Network, FPN+PAN):
- 다중 스케일 특징을 통합하여 더 정확한 객체 위치 예측
3️⃣ 객체 임베딩(Object Embedding) 헤드:
- 기존 YOLO 분류 헤드를 개선하여 프롬프트 임베딩을 활용할 수 있도록 설계
4️⃣ RepRTA (Re-parameterizable Region-Text Alignment)
- 텍스트 프롬프트 기반 탐지를 위한 모듈
5️⃣ SAVPE (Semantic-Activated Visual Prompt Encoder)
- 비주얼 프롬프트를 활용한 탐지를 위한 모듈
6️⃣ LRPC (Lazy Region-Prompt Contrast)
- 프롬프트 없이도 객체를 탐지하는 모듈
📌 1. RepRTA (Re-parameterizable Region-Text Alignment) - 텍스트 프롬프트 탐지
“자연어로 객체를 탐지할 수 있을까?”
YES! YOLOE는 텍스트 기반 탐지를 지원합니다.
기존 모델들은 텍스트 기반 객체 탐지를 위해 복잡한 크로스 모달 학습(Cross-Modality Fusion) 을 사용했습니다.
그러나 이는 계산량이 많고, 속도가 느려지는 문제가 있었습니다.
💡 RepRTA는 어떻게 다를까요?
✅ 텍스트 임베딩을 미리 캐싱하여 속도를 높임
✅ 추가 연산 없이 YOLO 아키텍처에 적용 가능
✅ 기존 YOLO 분류 헤드(Classification Head)와 동일한 형태로 동작
📢 RepRTA의 동작 방식
1️⃣ 사전 학습된 CLIP 기반 텍스트 임베딩 사용
- CLIP 기반 텍스트 임베딩을 사전에 생성하여 저장해둠
- 예:
"고양이", "강아지", "책상"등의 단어를 벡터로 변환
2️⃣ 경량화된 보정 네트워크(Auxiliary Network)로 정렬(Alignment) 수행
- 텍스트 임베딩을 최적화하여 YOLO의 특징과 더 잘 정렬되도록 조정
- 이 과정은 YOLO의 마지막 분류 레이어에 통합됨
3️⃣ Re-parameterization을 통해 YOLO 아키텍처에 직접 적용
- 학습이 끝나면, 추가 네트워크 없이도 YOLO의 기존 분류 구조에서 작동
결과:
기존 YOLO 모델처럼 동작하면서도, 텍스트 기반 객체 탐지가 가능!
추가 연산 없이도 YOLO처럼 빠르게 동작합니다.
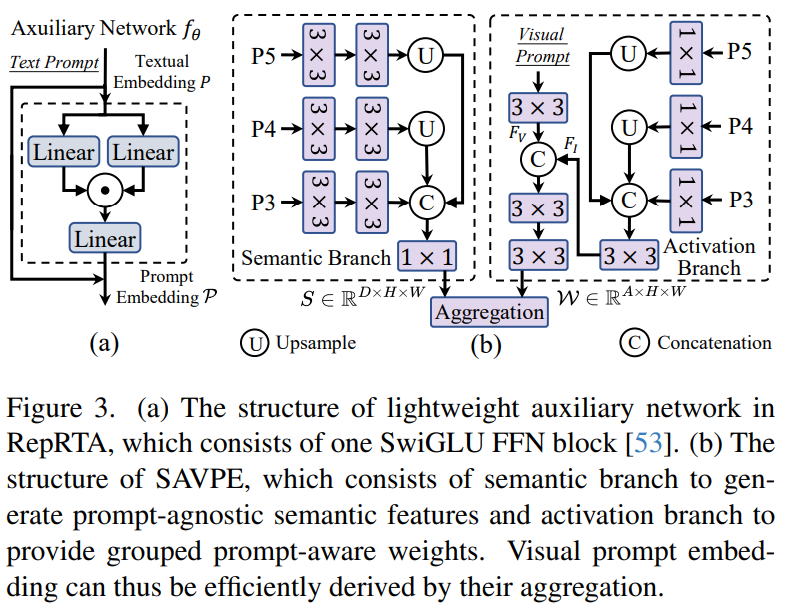
📌 2. SAVPE (Semantic-Activated Visual Prompt Encoder) - 비주얼 프롬프트 탐지
“이미지를 보고 비슷한 객체를 찾아줄 수 있을까?”
YES! YOLOE는 비주얼 프롬프트 탐지를 지원합니다.
기존 비주얼 프롬프트 기반 탐지 모델(T-Rex2, DINO-X)은 Transformer-heavy 구조를 사용하여 연산량이 많았습니다.
YOLOE는 이를 해결하기 위해 SAVPE를 도입하여 경량화된 구조를 사용합니다.
📢 SAVPE의 동작 방식
1️⃣ 입력 이미지를 다중 스케일 특징 맵으로 변환
- YOLO 백본을 활용하여 다양한 크기의 특징 맵을 생성
2️⃣ 비주얼 프롬프트(이미지 예시)로부터 특징을 추출
- 예: “이 강아지랑 비슷한 객체를 찾아줘!”
3️⃣ 두 개의 브랜치로 특징을 분석
- Semantic Branch: 객체의 의미 정보를 추출
- Activation Branch: 특정 영역(마스크)이 강조된 특징을 추출
4️⃣ 최종적으로 두 개의 정보를 결합하여 프롬프트 임베딩 생성
결과:
특정 이미지 예시(비주얼 프롬프트)를 주면, YOLOE는 비슷한 객체를 찾아줍니다!
(예: 강아지 사진을 주면, 비슷한 강아지를 자동 탐지)
📌 3. LRPC (Lazy Region-Prompt Contrast) - 프롬프트 없이도 탐지
“아무 입력 없이도 모든 객체를 탐지할 수 있을까?”
YES! YOLOE는 프롬프트 없이도 객체를 자동 탐지합니다.
기존 모델(GenerateU, DINO-X)은 텍스트 생성 모델(LLM)을 사용하여 객체명을 생성했지만,
이는 연산량이 많고 속도가 느렸습니다.
💡 YOLOE는 어떻게 해결할까요?
✅ YOLO 모델 자체적으로 객체를 탐지
✅ 내장된 대규모 카테고리 리스트(사전) 활용
✅ 불필요한 비교 연산을 최소화하여 속도 향상
📢 LRPC의 동작 방식
1️⃣ YOLOE는 자체적으로 객체를 탐지하고, 특징 벡터(Object Embedding)를 생성
2️⃣ 내장된 대규모 카테고리 사전(Vocabulary)과 비교하여 객체 이름을 매칭
- YOLOE는 가장 유사한 카테고리를 선택하여 객체를 분류
3️⃣ 불필요한 비교를 줄이기 위해 Lazy Matching 기법 적용
- 예: “모든 객체와 비교하는 것이 아니라, 특정 조건을 만족하는 객체만 탐색”
결과:
YOLOE는 아무 입력 없이도 자동으로 객체를 탐지하고 이름을 부여할 수 있습니다!
📊 YOLOE vs 기존 모델 비교
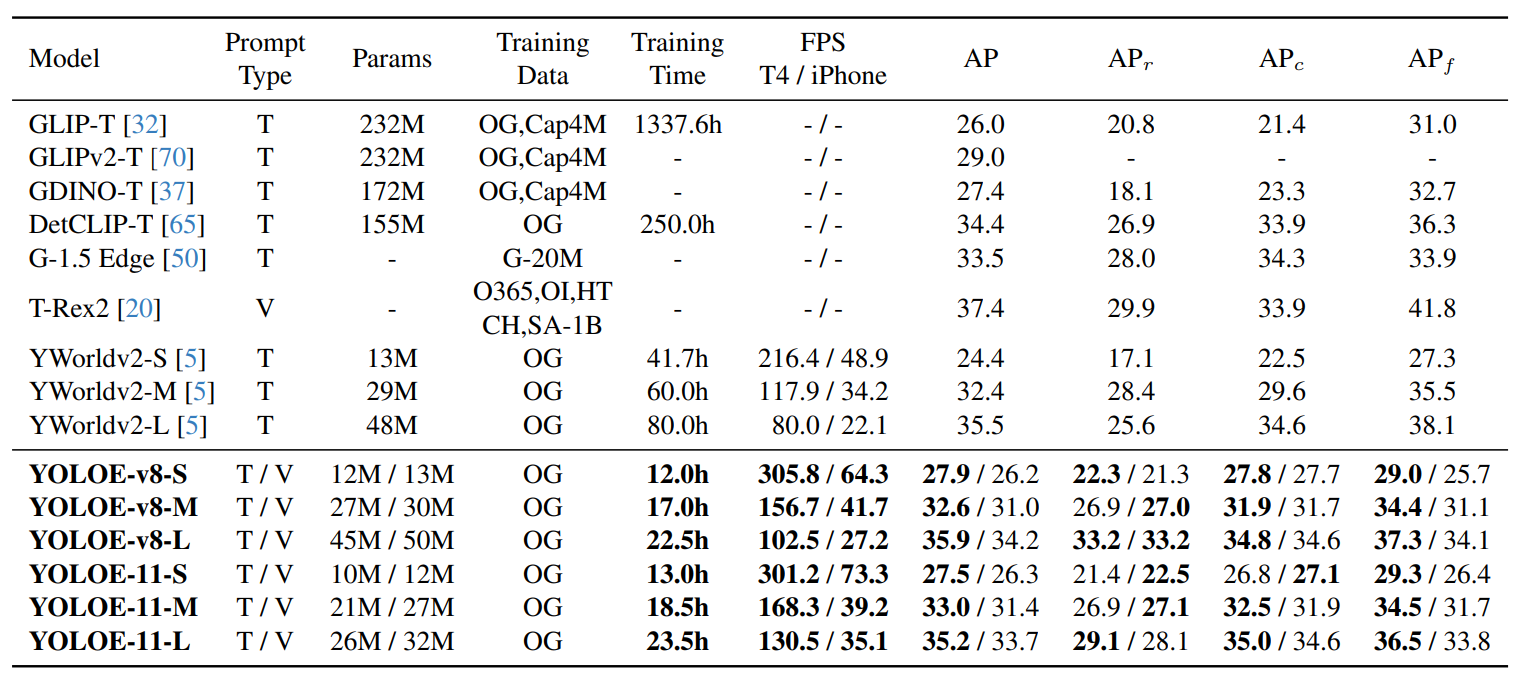
| 모델 | AP (정확도) ↑ | FPS (속도) ↑ | GPU 메모리 ↓ |
|---|---|---|---|
| YOLO-Worldv2 | 33.0 | 80.0 | 42.6GB |
| YOLOE (Ours) | 35.9 | 102.5 | 9.8GB |
📌 YOLOE는 기존 모델 대비:
✅ 정확도 10% 향상
✅ GPU 메모리 사용량 4배 감소
✅ 속도 1.4× 증가 (더 빠른 추론 성능!)
🛠️ YOLOE, 실제로 어디에 활용될 수 있을까?
🎬 1. 실시간 동영상 분석
- 스포츠 경기 분석: 선수 움직임 분석
- CCTV 보안: 위험 상황 감지
🎮 2. AI 기반 콘텐츠 제작
- AR/VR: 가상 환경에서 객체 탐지
- 게임 개발: 실시간 애니메이션 분석
🚗 3. 자율주행 & 로봇 비전
- 자율주행 자동차: 보행자, 차량 탐지
- 산업용 로봇: 물체 자동 인식
🔮 미래 발전 방향 & 현재 한계
현재 한계
🔍 매우 작은 물체(소품 등)의 인식 정확도 개선 필요
🔍 초장시간(10분 이상) 영상에서의 프레임 간 일관성 개선 필요
향후 개선 방향
🔬 고해상도 객체 탐지를 위한 추가 최적화
🔬 장시간 탐지를 위한 시간 축 정규화(Temporal Regularization) 강화
🔬 경량화된 YOLOE-M, YOLOE-S 모델 추가 개발 예정
📂 직접 사용해보기
📜 논문: https://arxiv.org/abs/2503.07465
🔗 GitHub: https://github.com/THU-MIG/yoloe
YOLOE는 오픈소스로 제공되며, 누구나 다운로드하여 사용할 수 있습니다!
🛠️ 결론: YOLOE의 강력한 탐지 성능
YOLOE는 세 가지 핵심 기술(RepRTA, SAVPE, LRPC)을 활용하여
기존 YOLO 모델의 한계를 완전히 해결했습니다.
✅ 텍스트 프롬프트 가능 (자연어 기반 객체 탐지)
✅ 비주얼 프롬프트 가능 (이미지 예시 기반 탐지)
✅ 프롬프트 없이도 자동 탐지 가능
YOLOE는 실시간 객체 탐지의 새로운 표준이 될 것입니다! 🚀