Gemma 3: 구글의 오픈 AI 모델 완전 가이드
Gemma 3: 구글의 혁신적인 오픈 AI 모델 완전 가이드
안녕하세요! 오늘은 구글 딥마인드가 최근 출시한 Gemma 3에 대해 자세히 알아보려 합니다. 인공지능 기술에 관심이 있거나 자신의 프로젝트에 AI 기능을 통합하고 싶은 분들에게 유용한 정보가 될 것입니다.
“내 컴퓨터에서 직접, 나만을 위한 AI를 실행할 수 없을까?”
이 질문에 대한 해답으로 Gemma 3와 같은 경량 언어 모델(SLM)이 주목받고 있습니다. 가벼우면서도 강력한 성능을 가진 이 모델은 개인 PC나 로컬 환경에서도 AI를 직접 실행할 수 있는 가능성을 열어주고 있습니다.
Gemma 3란 무엇인가?
Gemma 3는 구글의 최신 개방형 AI 모델 제품군으로, Gemini 2.0 모델과 동일한 연구와 기술을 기반으로 만들어졌습니다. 작년 첫 출시 이후 1억 건 이상의 다운로드와 6만 개가 넘는 커스텀 Gemma 모델이 만들어지며 ‘Gemmaverse’라는 활발한 생태계를 형성하고 있습니다.
이 모델은 텍스트와 이미지를 모두 처리할 수 있는 멀티모달 능력을 갖추고 있으며, 다양한 크기로 제공되어 각자의 컴퓨팅 환경과 요구사항에 맞게 선택할 수 있습니다. 가장 중요한 특징은 단일 GPU 또는 TPU에서 실행 가능하도록 설계되었다는 점입니다.
주요 특징
1. 다양한 모델 크기
Gemma 3는 다음 네 가지 매개변수 크기로 제공됩니다:
- 1B: 가장 작은 모델로, 텍스트만 처리 가능 (32K 컨텍스트 윈도우)
- 4B: 멀티모달 기능을 갖춘 소형 모델 (128K 컨텍스트 윈도우)
- 12B: 중형 멀티모달 모델 (128K 컨텍스트 윈도우)
- 27B: 가장 큰 모델로, 단일 GPU에서 실행 가능한 최고 성능 제공 (128K 컨텍스트 윈도우)
각 모델은 다양한 정밀도 수준(32비트, 16비트, 8비트, 4비트)으로 제공되어 메모리와 성능 사이의 균형을 조절할 수 있습니다.
2. 멀티모달 능력
4B, 12B, 27B 크기 모델은 텍스트뿐만 아니라 이미지도 입력으로 받아들일 수 있습니다. SigLIP 이미지 인코더를 사용하여 이미지를 토큰으로 변환하고, 이를 언어 모델에 입력합니다. 이를 통해:
- 이미지 내용 분석 및 설명
- 이미지 기반 질문 답변
- 시각적 데이터 추출 및 해석
- 텍스트와 이미지 조합 이해
이미지는 896x896 해상도로 정규화되며, ‘pan and scan’ 알고리즘을 통해 이미지의 세부 사항에 집중할 수 있습니다.
3. 대규모 컨텍스트 윈도우
이전 버전보다 16배 커진 128K 토큰의 컨텍스트 윈도우(1B 모델은 32K)를 제공합니다. 이는:
- 한 번에 매우 긴 문서나 여러 페이지의 콘텐츠 처리 가능
- 수백 개의 이미지를 동시에 분석 가능
- 복잡한 프롬프트와 대화 기록 유지 가능
이 확장된 컨텍스트는 RoPE 위치 임베딩을 1M 기본 주파수로 업그레이드하고, 슬라이딩 윈도우 인터리브드 어텐션 메커니즘을 최적화하여 구현되었습니다.
4. 다국어 지원
140개 이상의 언어를 지원하여 전 세계 사용자들이 자신의 모국어로 AI와 상호작용할 수 있습니다. 특히:
- 영어 외에도 35개 언어에 대한 즉시 사용 가능한 지원
- 140개 이상의 언어에 대한 사전 학습 지원
- 중국어, 일본어, 한국어 등 아시아 언어에 대한 향상된 토크나이저
이를 위해 Gemini 2.0의 SentencePiece 토크나이저(262K 엔트리)를 사용하고, 사전 학습 데이터셋에 다국어 데이터의 양을 두 배로 늘렸습니다.
5. 함수 호출 기능
개발자들은 특정 문법과 제약조건으로 코딩 함수를 정의할 수 있으며, Gemma 3는 이러한 함수를 호출하여 작업을 완료할 수 있습니다. 이를 통해:
- 자연어 인터페이스를 프로그래밍 시스템과 연결
- 구조화된 출력 생성
- AI 기반 워크플로우 자동화
- 에이전트 경험 구축
성능과 벤치마크
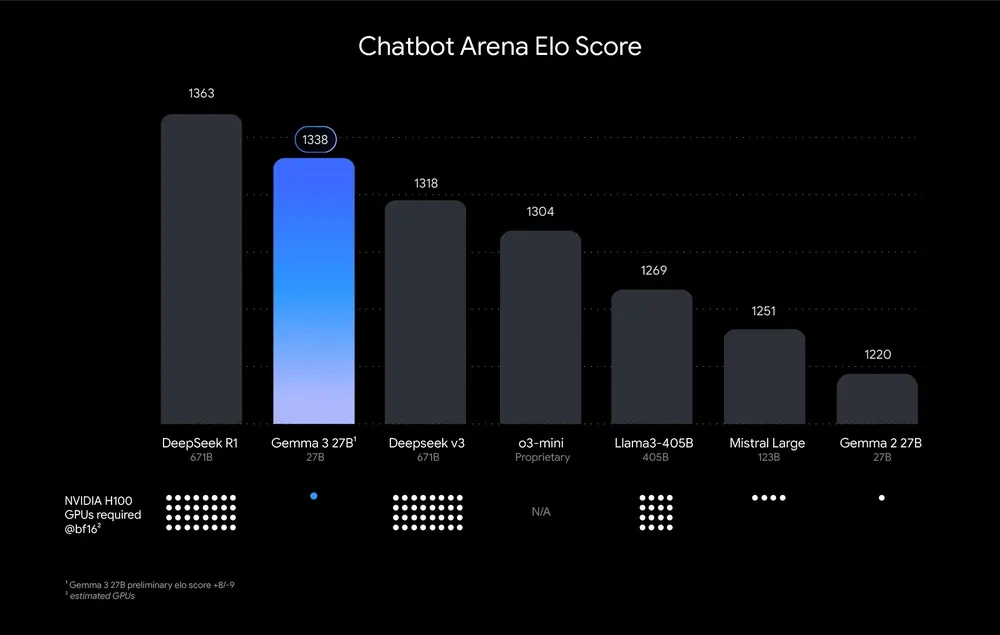
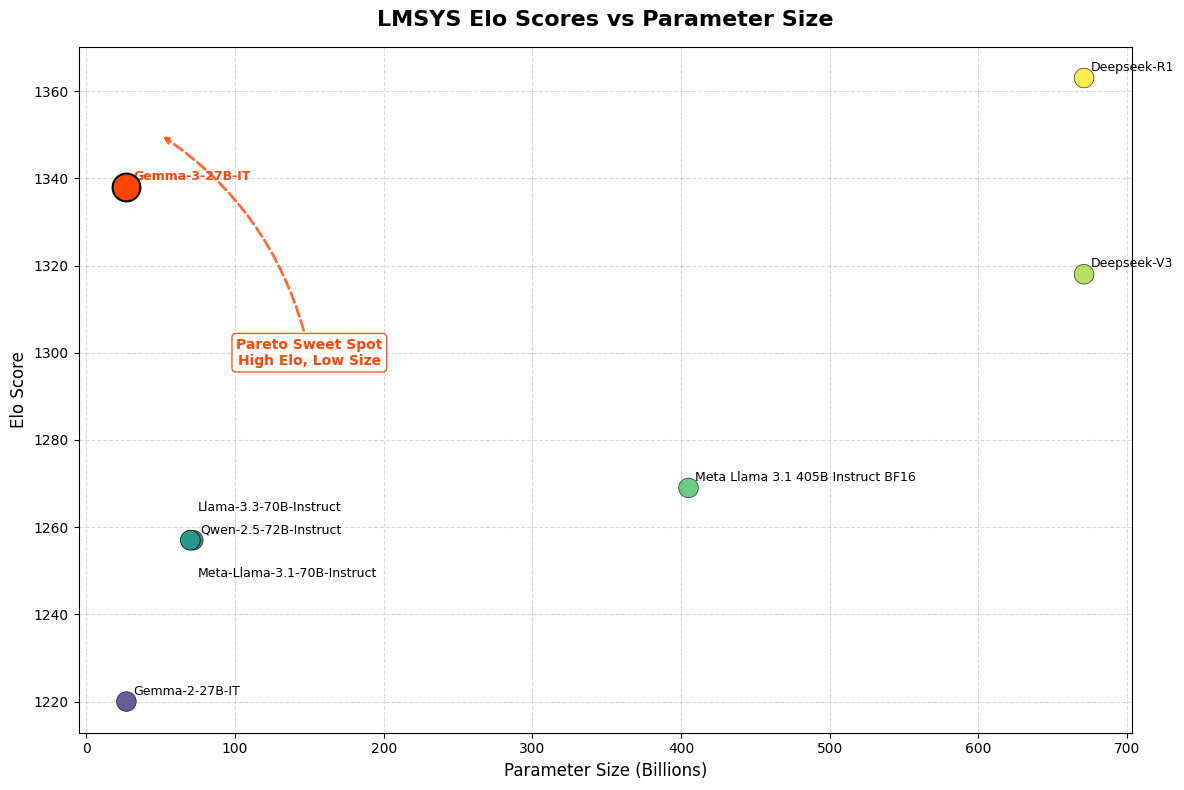
Gemma 3 27B 모델은 LMSys Chatbot Arena Elo 점수에서 1338점을 기록하며 상위 10위권 모델에 진입했습니다. 이는 o1-preview와 유사한 수준이며, 다른 비사고형(non-thinking) 오픈 모델들을 능가합니다.
주요 벤치마크 성능(27B 모델 기준):
- MMLU-Pro: 67.5
- LiveCodeBench: 29.7
- Bird-SQL: 54.4
- GPQA Diamond: 42.4
- MATH: 69.0
- FACTS Grounding: 74.9
- MMMU: 64.9
이외에도 공식 모델 카드에 기재된 다양한 벤치마크 결과는 다음과 같습니다:
추론 및 사실성 (Pre-trained 모델) | 벤치마크 | 1B | 4B | 12B | 27B | |———|—–|—–|——|——| | HellaSwag (10-shot) | 62.3 | 77.2 | 84.2 | 85.6 | | BoolQ (0-shot) | 63.2 | 72.3 | 78.8 | 82.4 | | TriviaQA (5-shot) | 39.8 | 65.8 | 78.2 | 85.5 | | ARC-e (0-shot) | 73.0 | 82.4 | 88.3 | 89.0 | | BIG-Bench Hard (few-shot) | 28.4 | 50.9 | 72.6 | 77.7 |
STEM 및 코드 | 벤치마크 | 4B | 12B | 27B | |———|—–|——|——| | MMLU (5-shot) | 59.6 | 74.5 | 78.6 | | GSM8K (8-shot) | 38.4 | 71.0 | 82.6 | | HumanEval (0-shot) | 36.0 | 45.7 | 48.8 |
다국어 능력 | 벤치마크 | 1B | 4B | 12B | 27B | |———|—–|—–|——|——| | MGSM | 2.04 | 34.7 | 64.3 | 74.3 | | Global-MMLU-Lite | 24.9 | 57.0 | 69.4 | 75.7 | | XQuAD (all) | 43.9 | 68.0 | 74.5 | 76.8 |
멀티모달 능력 | 벤치마크 | 4B | 12B | 27B | |———|—–|——|——| | DocVQA (val) | 72.8 | 82.3 | 85.6 | | TextVQA (val) | 58.9 | 66.5 | 68.6 | | ChartQA | 63.6 | 74.7 | 76.3 |
특히 주목할 점은, 이전 버전인 Gemma 2 27B(1220점)와 비교해 약 10% 이상 성능이 향상되었으며, 일부 벤치마크에서는 Gemini 1.5-Pro를 능가하는 성능을 보여줍니다.
또한, DeepSeek R1(67B), DeepSeek v3(67B), Llama3-405B(405B) 등의 대형 모델이 최대 32개에서 64개의 NVIDIA H100 GPU가 필요한 반면, Gemma 3 27B는 단 하나의 GPU로도 구동 가능합니다.
안전성과 책임감 있는 개발
구글은 Gemma 3 개발 과정에서 다음과 같은 안전 프로토콜을 적용했습니다:
- 엄격한 데이터 거버넌스
- 파인튜닝을 통한 안전 정책 준수
- 강력한 벤치마크 평가
또한, ShieldGemma 2라는 이미지 안전 검사기를 함께 출시했습니다. 이는 Gemma 3 아키텍처 기반의 4B 크기 모델로, 위험한 콘텐츠, 성적으로 노골적인 내용, 폭력 등 세 가지 안전 카테고리에 대한 라벨을 출력합니다.
훈련 데이터 및 모델 구조
Gemma 3 모델은 다양한 소스의 텍스트와 이미지 데이터로 훈련되었습니다. 각 모델 크기별 훈련 토큰 수는 다음과 같습니다:
- 27B 모델: 14조 토큰
- 12B 모델: 12조 토큰
- 4B 모델: 4조 토큰
- 1B 모델: 2조 토큰
훈련 데이터의 주요 구성 요소는 다음과 같습니다:
- 웹 문서: 다양한 언어 스타일, 주제, 어휘를 포함하는 웹 텍스트 모음으로, 140개 이상의 언어로 된 콘텐츠를 포함합니다.
- 코드: 프로그래밍 언어의 구문과 패턴을 학습하여 코드 생성 및 코드 관련 질문에 대한 이해력을 향상시킵니다.
- 수학: 논리적 추론, 기호 표현, 수학적 질문 해결 능력을 학습합니다.
- 이미지: 다양한 이미지를 통해 이미지 분석 및 시각적 데이터 추출 작업을 수행할 수 있습니다.
훈련 과정에서는 구글의 Tensor Processing Unit(TPU) 하드웨어(TPUv4p, TPUv5p, TPUv5e)를 사용했으며, JAX와 ML Pathways 소프트웨어를 활용했습니다. 이는 대규모 행렬 연산에 최적화된 TPU의 성능과 JAX의 ‘단일 컨트롤러’ 프로그래밍 모델을 통해 훈련 과정을 크게 단순화했습니다.
로컬 환경에서 실행하기
1. Ollama를 통한 실행
Ollama를 설치한 후, 다음 명령어로 쉽게 실행할 수 있습니다:
1
2
3
4
ollama run gemma3:1b # 1B 모델 실행
ollama run gemma3:4b # 4B 모델 실행
ollama run gemma3:12b # 12B 모델 실행
ollama run gemma3:27b # 27B 모델 실행
Ollama를 통해 제공되는 모델은 양자화 처리되어 있어 적은 리소스로도 효율적으로 실행할 수 있습니다. 예를 들어, Gemma 3 12B 모델은 약 11.6GB의 VRAM을 사용하며, 입력부터 결과 출력까지 약 10-15초 정도 소요됩니다.
2. Python을 통한 로컬 실행
모델을 Hugging Face에서 다운로드한 후, Transformers 라이브러리를 사용하여 실행할 수 있습니다. 최신 버전의 Transformers(4.50.0 이상)이 필요합니다:
1
pip install -U transformers
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
from transformers import AutoProcessor, Gemma3ForConditionalGeneration
from PIL import Image
import torch
model_id = "gemma-3-4b-it" # 로컬 경로 (모델이 저장된 폴더)
model = Gemma3ForConditionalGeneration.from_pretrained(
model_id, device_map="auto"
).eval()
processor = AutoProcessor.from_pretrained(model_id)
messages = [
{
"role": "system",
"content": [{"type": "text", "text": "You are a helpful assistant."}]
},
{
"role": "user",
"content": [
{"type": "image", "image": "image/test1.png"}, # 이미지 경로
{"type": "text", "text": "Describe this image in detail."} # 프롬프트
]
}
]
inputs = processor.apply_chat_template(
messages, add_generation_prompt=True, tokenize=True,
return_dict=True, return_tensors="pt"
).to(model.device, dtype=torch.bfloat16)
input_len = inputs["input_ids"].shape[-1]
with torch.inference_mode():
generation = model.generate(**inputs, max_new_tokens=100, do_sample=False)
generation = generation[0][input_len:]
decoded = processor.decode(generation, skip_special_tokens=True)
print(decoded)
이 방식으로 gemma-3-4b-it 모델을 로컬에서 실행하면 약 14GB의 VRAM을 사용하며, 추론에는 약 20초가 소요됩니다.
통합 및 배포 옵션
Gemma 3는 다양한 도구 및 프레임워크와 통합할 수 있습니다:
개발 도구
- Hugging Face Transformers
- Ollama
- JAX
- Keras
- PyTorch
- Google AI Edge
- UnSloth
- vLLM
- Gemma.cpp
배포 옵션
- Google AI Studio (브라우저에서 즉시 사용)
- Vertex AI
- Cloud Run
- Google GenAI API
- 로컬 환경
- NVIDIA API Catalog
- AMD GPUs (ROCm 스택)
- CPU (Gemma.cpp)
온디바이스 및 저사양 기기
Apple Silicon 기기(Mac, iPhone)에서는 mlx-vlm 라이브러리를 통해 실행할 수 있습니다:
1
2
pip install git+https://github.com/Blaizzy/mlx-vlm.git
python -m mlx_vlm.generate --model mlx-community/gemma-3-4b-it-4bit --max-tokens 100 --temp 0.0 --prompt "What is in this image?" --image path_to_image.jpg
llama.cpp를 통해 양자화된 모델을 로컬 터미널에서 실행할 수도 있습니다.
활용 사례
Gemma 3는 다양한 분야에서 활용될 수 있습니다:
- 콘텐츠 생성: 시, 스크립트, 코드, 마케팅 카피, 이메일 초안 등
- 챗봇과 대화형 AI: 고객 서비스, 가상 비서, 대화형 애플리케이션
- 텍스트 요약: 문서, 연구 논문, 보고서의 간결한 요약 생성
- 이미지 데이터 추출: 시각적 데이터 해석 및 요약
- 교육 및 연구 도구: 언어 학습, 텍스트 탐색, AI 연구 등
Gemma 학술 프로그램
구글은 학술 연구 발전을 위해 ‘Gemma 3 Academic Program’을 출시했습니다. 학술 연구자들은 Gemma 3 기반 연구를 가속화하기 위해 Google Cloud 크레딧(10,000달러 상당)을 신청할 수 있습니다.
윤리적 고려사항 및 한계점
Gemma 3와 같은 개방형 비전-언어 모델(VLM)의 개발은 여러 윤리적 고려사항을 수반합니다. 구글은 모델 개발 과정에서 다음과 같은 요소들을 신중하게 고려했습니다:
1. 편향성과 공정성
대규모 실제 텍스트 및 이미지 데이터에서 훈련된 VLM은 훈련 자료에 내재된 사회문화적 편향을 반영할 수 있습니다. 이를 방지하기 위해 Gemma 3는 입력 데이터 전처리와 면밀한 검토 과정을 거쳤습니다.
2. 허위정보 및 오용
VLM은 거짓되거나 오해의 소지가 있거나 유해한 텍스트를 생성하는 데 오용될 수 있습니다. 책임감 있는 사용을 위한 가이드라인이 ‘책임감 있는 생성형 AI 툴킷’에 제공됩니다.
3. 투명성과 책임성
모델 카드는 모델의 아키텍처, 기능, 한계, 평가 프로세스에 대한 상세 정보를 요약하여 제공합니다. 이러한 투명성은 책임감 있는 AI 개발을 지원합니다.
모델의 주요 한계점
훈련 데이터: 훈련 데이터의 품질과 다양성은 모델의 기능에 크게 영향을 미칩니다. 훈련 데이터의 편향이나 격차는 모델 응답의 한계로 이어질 수 있습니다.
맥락 및 작업 복잡성: 모델은 명확한 프롬프트와 지시사항이 있는 작업에 더 적합하며, 열린 형태나 매우 복잡한 작업은 어려울 수 있습니다.
언어 모호성과 뉘앙스: 자연어는 본질적으로 복잡합니다. 모델은 미묘한 뉘앙스, 풍자, 비유적 언어를 이해하는 데 어려움을 겪을 수 있습니다.
사실적 정확성: 모델은 훈련 데이터셋에서 학습한 정보를 기반으로 응답을 생성하지만, 이는 지식 기반이 아닙니다. 따라서 잘못되거나 오래된 사실 진술을 생성할 수 있습니다.
상식: 모델은 언어의 통계적 패턴에 의존합니다. 따라서 특정 상황에서 상식적 추론을 적용하는 능력이 부족할 수 있습니다.
결론
Gemma 3는 구글이 최첨단 AI 기술을 개방형 모델로 제공함으로써 더 많은 개발자와 연구자들이 AI의 혜택을 누릴 수 있게 했다는 점에서 큰 의미가 있습니다. 상대적으로 작은 크기로도 강력한 성능을 제공하기 때문에 노트북, 데스크톱 또는 개인 클라우드 인프라와 같은 제한된 리소스 환경에서도 배포가 가능합니다.
특히 SLM(Small Language Model) 열풍 속에서, Gemma 3는 “내 컴퓨터에서 직접, 나만을 위한 AI를 실행할 수 없을까?”라는 질문에 대한 강력한 해답을 제시합니다. 앞으로는 개인화된 AI 모델의 시대가 도래할 것으로 기대되며, Gemma 3와 같은 모델들은 누구나 쉽게 자신만의 AI를 구축하고, 로컬 환경에서 안전하게 실행할 수 있는 시대를 앞당길 것입니다.
AI 기술의 민주화를 통해 더 많은 혁신이 일어날 수 있는 기반을 마련한 Gemma 3, 앞으로의 발전이 기대됩니다!
인용
1
2
3
4
5
6
7
@article{gemma_2025,
title={Gemma 3},
url={https://goo.gle/Gemma3Report},
publisher={Kaggle},
author={Gemma Team},
year={2025}
}