KV-Edit: 훈련 없이 배경을 완벽하게 보존하는 AI 이미지 편집
KV-Edit: 훈련 없이 배경을 완벽하게 보존하는 AI 이미지 편집
KV-Edit: 훈련 없이 배경을 완벽하게 보존하는 AI 이미지 편집
🔍 KV-Edit란?

KV-Edit는 기존 Diffusion Transformer(DiT) 기반 모델을 활용하면서도, 추가적인 훈련 없이(Training-Free) 배경을 완벽히 보존하며 이미지 편집을 수행할 수 있도록 설계된 AI 모델입니다.
💡 핵심 개념:
- 기존 디퓨전 모델(Diffusion Model)을 활용하여 편집된 이미지를 생성
- KV Cache(Key-Value Cache)를 도입하여 원본 배경 정보를 유지
- Foreground(편집 대상)만 변형하면서 배경과의 일관성 유지
이를 위해 KV-Edit는 기존 Stable Diffusion, DiT 기반의 모델 구조를 활용하지만, Key-Value Caching 기법을 추가하여 배경을 보존할 수 있도록 최적화되었습니다.
🔬 KV-Edit의 동작 원리 (How It Works?)
1️⃣ KV-Edit의 전체 모델 구조 (Overall Model Architecture)
KV-Edit는 기존의 DiT 기반 디퓨전 모델을 확장하여 KV Cache를 추가한 구조를 가집니다.

📌 구성 요소:
- DiT 기반 UNet 아키텍처
- 기존의 Stable Diffusion, DiT 방식과 유사한 구조
- 텍스트 프롬프트를 입력으로 받아 이미지 변형 수행
- KV Cache 저장 모듈 (Key-Value Memory Module)
- 원본 이미지에서 배경 정보를 Key-Value 쌍으로 저장
- 배경이 변경되지 않도록 보존
- Foreground 편집 모듈 (Foreground Editing Pipeline)
- 사용자가 변경하고 싶은 영역(오브젝트 등)만 변형
- 배경과 자연스럽게 연결될 수 있도록 보정
2️⃣ KV-Edit의 주요 동작 과정 (How KV-Edit Works?)
KV-Edit의 모델 구조는 3단계 프로세스를 거쳐 배경을 유지한 채 이미지를 편집합니다.
🔹 (1) 배경 정보 저장 (KV Cache Initialization)
💡 기존 방식과 차이점:
- 기존 방법: 모든 픽셀을 한꺼번에 수정하면서 배경이 변형될 가능성이 높음
- KV-Edit 방식: 배경 정보를 KV Cache에 저장하여 유지, Foreground만 수정
✅ 과정:
- 원본 이미지를 Transformer 기반 모델(DiT)로 분석
- 배경과 편집할 Foreground 영역을 구분
- 배경 부분의 Key-Value 쌍을 저장(KV Cache 생성)
📌 결과:
- 편집 과정에서 배경이 수정되지 않도록 보장
- 기존 디퓨전 모델의 노이즈 추가 과정에서도 배경 정보 유지
🔹 (2) Foreground(편집할 영역) 수정 (Selective Noise Inversion & Editing)
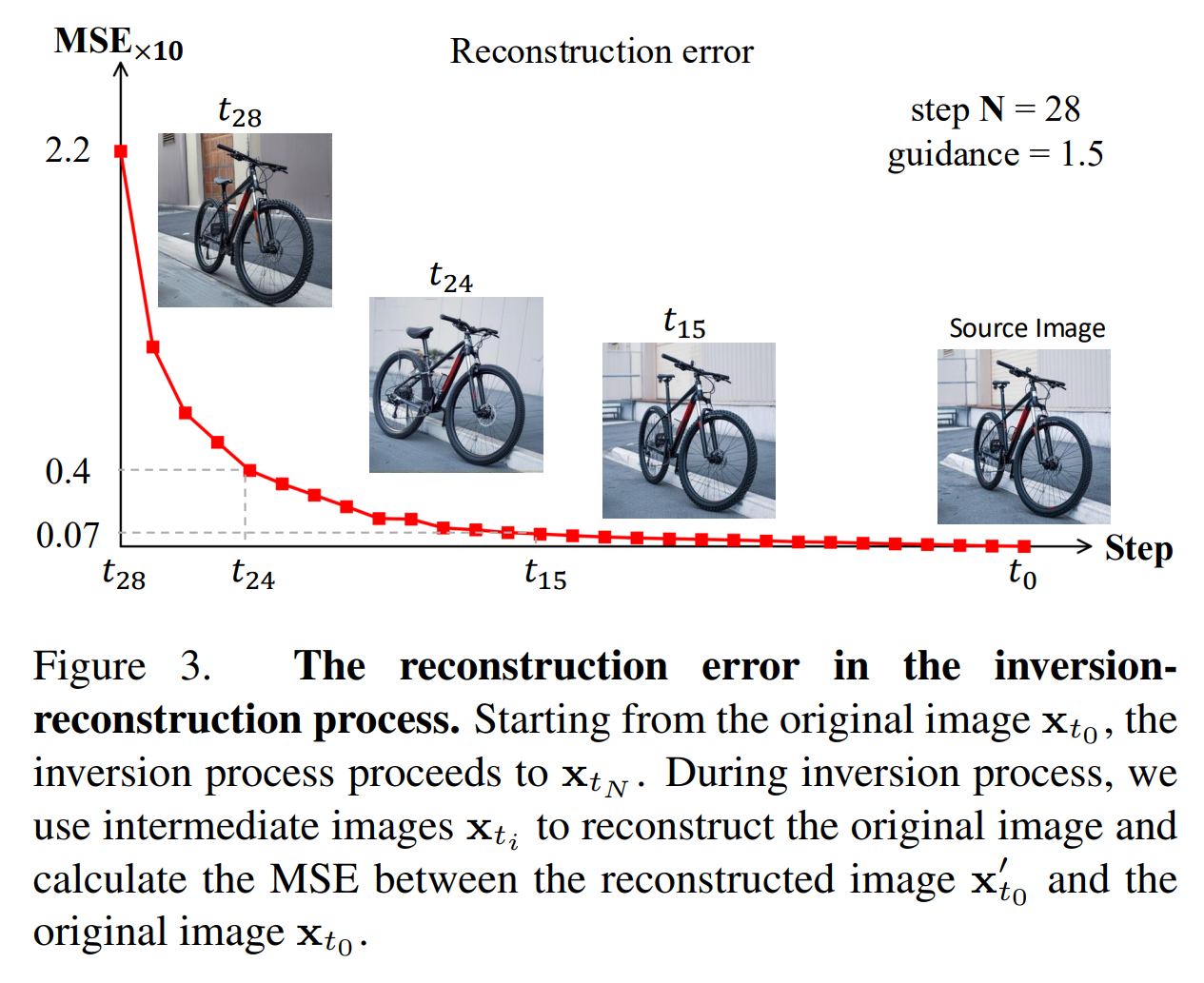
💡 기존 방식과 차이점:
- 기존 방법: 편집 과정에서 배경도 변형될 가능성이 있음
- KV-Edit 방식: Foreground 부분만 노이즈 추가 및 제거
✅ 과정:
- 배경 정보를 유지한 상태에서 Foreground만 노이즈 추가
- 사용자가 입력한 텍스트 프롬프트를 기반으로 새로운 요소 생성
- Foreground 편집 후, 배경과 자연스럽게 융합
📌 결과:
- 원하는 부분만 자연스럽게 편집 가능
- 배경과의 경계가 부자연스럽지 않도록 최적화
🔹 (3) 최종 이미지 생성 (Final Image Reconstruction with KV Cache Integration)
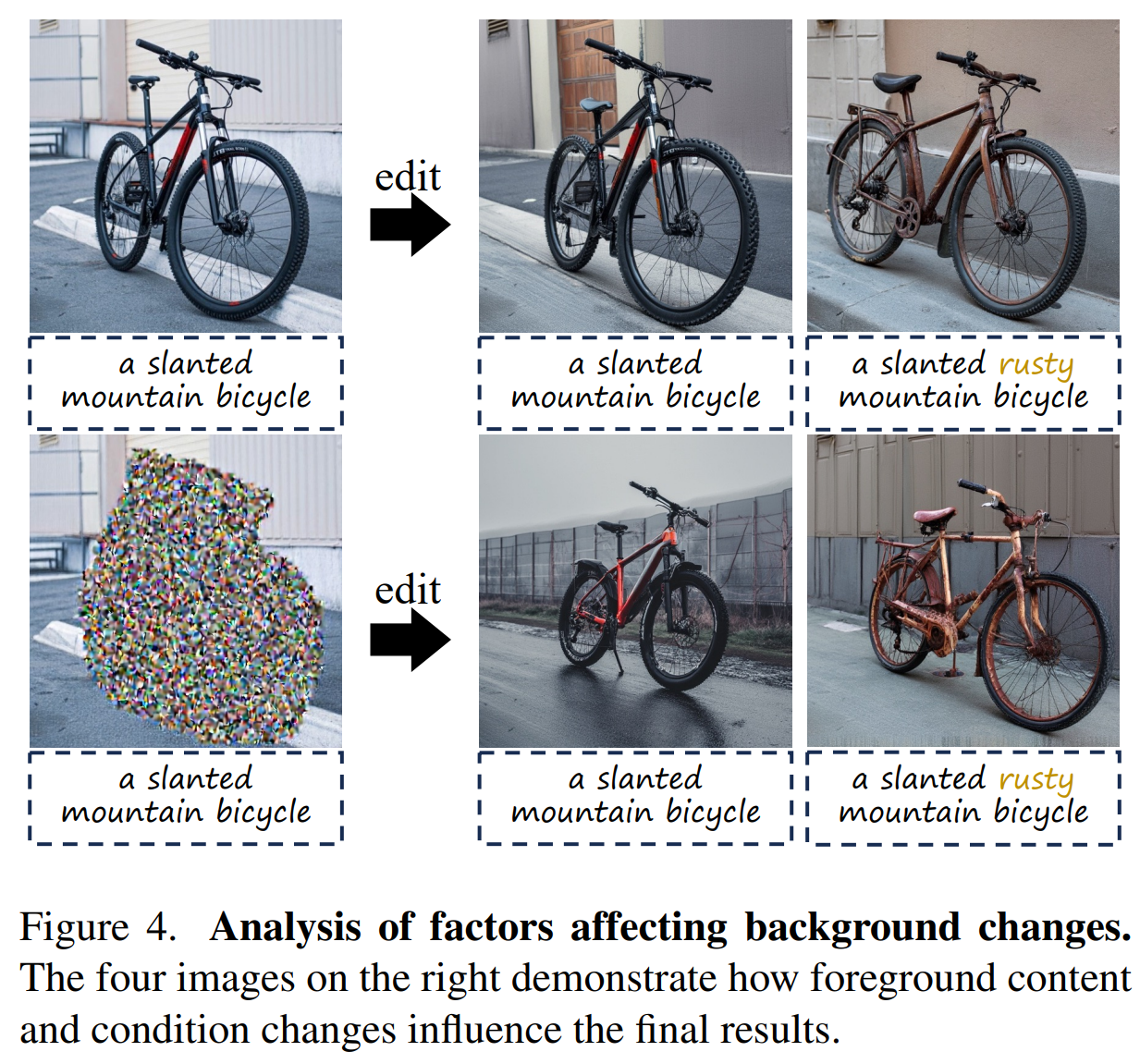
💡 기존 방식과 차이점:
- 기존 방법: 배경까지 새롭게 생성하면서 원본과 차이가 발생
- KV-Edit 방식: 저장된 KV Cache를 불러와 배경을 그대로 복원
✅ 과정:
- 편집된 Foreground 요소와 저장된 KV Cache(배경 정보)를 결합
- Denoising 과정을 거쳐 최종 이미지 생성
- 기존 배경과 부드럽게 융합하여 자연스러운 결과물 출력
📌 결과:
- 기존 배경을 100% 유지하면서, 새로운 요소만 추가된 완벽한 편집 결과 생성
3️⃣ KV-Edit의 메모리 최적화 (Memory Efficiency & Scalability)

🔹 O(1) 메모리 최적화란?
KV-Edit는 기존 모델처럼 모든 픽셀을 다시 계산하는 방식이 아니라, KV Cache를 활용하여 배경을 보존하는 방식을 사용합니다.
✅ 기존 방식 (O(N) 연산량 필요)
- 전체 이미지를 다시 생성해야 하므로 연산량이 매우 큼
- GPU 메모리 사용량이 많아 고사양 장비가 필요
✅ KV-Edit 방식 (O(1) 최적화)
- 배경 정보를 한 번만 저장하고 재사용
- 편집할 영역만 연산하므로 GPU 메모리 사용량이 대폭 감소
📌 결과:
- 고사양 장비 없이도 고품질 편집 가능
- 실시간 편집 속도 향상
🔑 KV-Edit 모델의 주요 기술적 차별점
| 비교 항목 | 기존 디퓨전 기반 편집 모델 | KV-Edit |
|---|---|---|
| 배경 유지 | ❌ 완벽한 보존 어려움 | ✅ KV Cache 활용하여 100% 유지 |
| 편집 방식 | 전체 이미지 수정 | 특정 영역만 선택적 수정 |
| 연산량 | ❌ 높은 연산 비용 | ✅ O(1) 메모리 최적화 |
| 훈련 필요 여부 | ✅ 추가 훈련 필요 | ❌ 훈련 없이 사용 가능 |
| 텍스트-이미지 정합성 | ⭕ 일부 개선 가능 | ✅ 높은 정밀도로 보존 가능 |
📌 결론

KV-Edit는 기존 디퓨전 모델의 한계를 극복한 최초의 배경 유지 이미지 편집 AI
- 기존 배경을 그대로 유지하면서 원하는 부분만 편집 가능
- KV Cache를 활용하여 훈련 없이도 즉시 사용 가능
- O(1) 메모리 최적화로 더 적은 연산량으로 실행 가능
- Stable Diffusion, DiT 등 기존 모델과 쉽게 통합 가능
This post is licensed under CC BY 4.0 by the author.