olmOCR: 비전-언어 모델로 PDF 문서의 한계를 뛰어넘다
olmOCR: PDF 문서 처리를 혁신하는 비전-언어 모델
🔗 olmOCR GitHub: allenai/olmocr
🔗 olmOCR Demo: olmOCR Demo
1. 개요
PDF 문서는 방대한 정보가 포함된 주요 디지털 문서 형식이지만, 기존 언어 모델(LLM)에서는 이를 효과적으로 활용하기 어려웠습니다. PDF 문서의 레이아웃, 표, 다이어그램, 수식 등을 정확하게 유지하며 변환하는 것은 큰 도전 과제입니다.
olmOCR은 비전-언어 모델(VLM, Vision-Language Model)을 활용하여 PDF 문서를 자연스럽고 읽기 쉬운 텍스트로 변환하는 오픈소스 OCR 툴킷입니다.
olmOCR은 단순한 OCR을 넘어 문서의 레이아웃을 분석하고, 표와 수식을 구조적으로 복원하며, AI 기반 텍스트 정렬을 수행합니다.
2. 기존 OCR 기술의 한계와 olmOCR의 차별점
기존 OCR 도구의 문제점
기존의 PDF 텍스트 추출 도구(예: Tesseract, Grobid, Adobe Acrobat OCR)는 다음과 같은 문제를 가지고 있습니다.
- 레이아웃 보존 어려움:
- 표, 리스트, 다이어그램, 각주 등의 구조를 무너뜨리며 단순한 텍스트로 변환
- 읽기 순서 문제:
- PDF 내 텍스트 순서가 뒤섞여 문서의 흐름을 유지하기 어려움
- 고품질 데이터 생성 한계:
- AI 모델 학습에 필요한 깨끗한 텍스트 데이터를 생성하기 어려움
olmOCR이 해결하는 문제
olmOCR은 비전-언어 모델(VLM) 을 활용하여 기존 OCR 도구의 한계를 극복합니다.
✅ 문서 구조를 유지한 상태로 변환 → 표, 리스트, 이미지 캡션, 제목 등을 보존
✅ 문서의 논리적 흐름을 유지 → 읽기 순서를 AI가 정렬하여 정확한 텍스트 제공
✅ Markdown 형식으로 변환 지원 → AI 학습 및 데이터 분석을 위한 고품질 텍스트 출력
✅ 대규모 PDF 처리 가능 → 100만 페이지 변환 비용이 단 190달러
3. olmOCR의 동작 원리
olmOCR은 비전-언어 모델(VLM)을 활용한 OCR 파이프라인을 따르며, 기존 OCR 방식과는 근본적으로 다른 접근법을 사용합니다.
1️⃣ PDF 문서 입력 및 전처리
olmOCR이 PDF를 처리하는 첫 번째 단계는 페이지별 이미지와 텍스트 추출입니다.
- PDF 문서를 페이지별 이미지로 변환
poppler-utils를 활용하여 PDF를 래스터화하여 고해상도 이미지로 변환
- 기본적인 OCR을 수행하여 초기 텍스트 추출
pdf2text또는Tesseract를 사용하여 기계 판독이 가능한 텍스트를 먼저 가져옴
- 텍스트 블록을 위치 기반으로 분석
- 페이지 내 텍스트 위치, 폰트 크기, 스타일 정보를 추출
- 표, 캡션, 제목, 본문 등 문서 요소를 식별
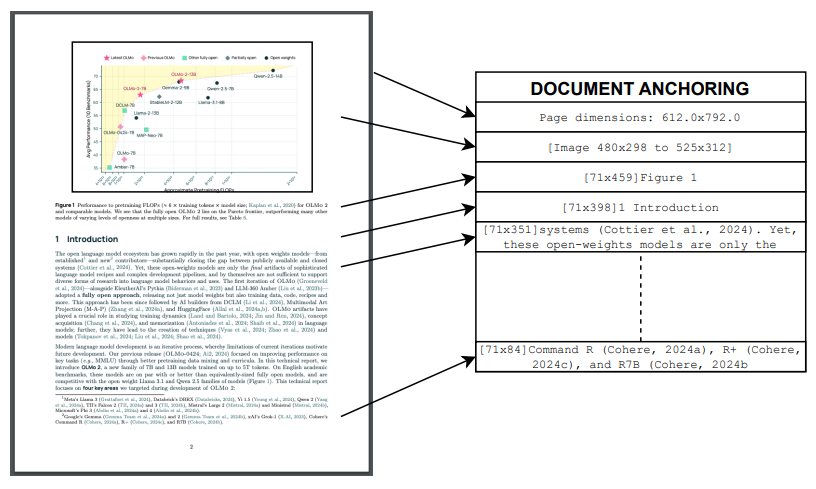
2️⃣ 문서 앵커링(Document Anchoring) 적용
olmOCR의 핵심 기술 중 하나는 “문서 앵커링(Document Anchoring)” 입니다.
이는 텍스트 블록을 물리적 위치와 연결하여, 문서의 읽기 순서를 유지하는 방법입니다.
- 문서의 텍스트 블록을 위치 기반으로 정렬
- 문서 내 텍스트 박스를 인식하여 페이지 내 논리적 순서로 정렬
- 제목, 본문, 표, 캡션 등의 요소를 자동 인식하여 문서 구조를 복원
- 다중 열(multi-column) 문서에서도 자연스러운 읽기 흐름을 유지
3️⃣ 비전-언어 모델(VLM) 기반 변환
olmOCR은 일반적인 OCR 모델이 아닌, Qwen2-VL-7B-Instruct와 같은 비전-언어 모델을 활용하여 OCR을 수행합니다.
- PDF 이미지와 텍스트를 비전-언어 모델에 입력
- Qwen2-VL, Llava, Qwen2-VL-Chat 등의 대형 멀티모달 모델을 활용
- 모델이 문서를 이해하고 정확한 텍스트와 레이아웃을 복원
- 텍스트 위치와 문서의 논리적 구조를 결합하여 Markdown 형식으로 변환
- 표, 다이어그램, 수식 등의 시각적 요소도 구조를 유지하며 변환
🔥 기존 OCR 도구는 단순한 문자 인식만 수행하지만, olmOCR은 문서의 맥락을 이해하고 구조를 유지한 상태로 변환한다는 점이 핵심 차별점입니다.
4️⃣ 최종 변환 및 출력
olmOCR은 PDF 문서를 Markdown, JSON, TXT 등의 형식으로 출력하여 AI 학습 및 데이터 분석에 최적화된 형태로 변환합니다.
✅ Markdown 변환 → 표, 리스트, 제목, 본문을 유지하며 정리된 텍스트 출력
✅ JSON 변환 → AI 학습을 위한 데이터 포맷으로 활용 가능
✅ TXT 변환 → 단순한 텍스트 파일 형태로 저장 가능
4. 성능 비교 및 벤치마크 결과
olmOCR은 기존 OCR 기술과 비교하여 더 낮은 비용으로 더 높은 정확도를 제공합니다.
💰 비용 비교 (100만 페이지 변환 기준)
| 모델 | 처리 속도 (tokens/sec) | 100만 페이지 변환 비용 |
|---|---|---|
| GPT-4o API | 80 | $12,480 |
| GPT-4o (배치 모드) | 160 | $6,240 |
| Marker API | 800 | $1,250 |
| olmOCR (A100 GPU) | 1,487 | $270 |
| olmOCR (H100 GPU) | 3,050 | $190 |
✅ olmOCR은 GPT-4o 대비 32배 저렴하며, 성능도 우수
📊 OCR 품질 평가 (정렬 정확도)
olmOCR은 기존 OCR 도구보다 더 정확한 문서 변환 품질을 보여줍니다.
| 모델 | 정렬 정확도(Alignment Score) |
|---|---|
| GPT-4o | 0.954 |
| GPT-4o Mini | 0.833 |
| olmOCR | 0.875 |
5. 실제 활용 사례
🏛 학술 논문 및 연구 문서 변환
- 논문 PDF를 Markdown/Text 형식으로 변환하여 검색, 요약, 분석을 쉽게 수행
- 표, 그래프 캡션 등을 유지하며 정확한 데이터 변환 가능
📜 법률 문서 및 계약서 처리
- 법률 문서를 AI 기반으로 분석할 때 텍스트 구조를 유지한 상태로 변환
- OCR 오차를 최소화하여 고품질 법률 데이터 제공
🧑💻 대규모 AI 데이터 구축
- AI 모델 학습을 위한 고품질 텍스트 데이터 생성 가능
- 기존 웹 크롤링 데이터보다 신뢰할 수 있는 OCR 데이터 구축
6. olmOCR 설치 및 사용법
olmOCR은 오픈소스로 제공되며, 누구나 쉽게 설치하고 사용할 수 있습니다.
🔗 설치 방법
1
2
3
4
5
6
7
8
9
10
11
12
# 필수 패키지 설치
sudo apt-get update
sudo apt-get install poppler-utils ttf-mscorefonts-installer
# Conda 환경 설정
conda create -n olmocr python=3.11
conda activate olmocr
# GitHub에서 olmOCR 클론 후 설치
git clone https://github.com/allenai/olmocr.git
cd olmocr
pip install -e .
🖥️ PDF 변환 실행
1
2
3
4
5
# 단일 PDF 변환
python -m olmocr.pipeline ./workspace --pdfs example.pdf
# 여러 개의 PDF 변환
python -m olmocr.pipeline ./workspace --pdfs documents/*.pdf
🔍 결과 확인
1
2
3
4
5
# 변환된 JSON 파일 확인
cat workspace/results/output_*.jsonl
# 원본 PDF와 변환 결과 비교
python -m olmocr.viewer.dolmaviewer workspace/results/output_*.jsonl
7. 마무리
olmOCR은 기존 OCR 도구의 한계를 극복하고, PDF 문서에서 고품질의 텍스트 데이터를 추출할 수 있는 강력한 AI 기반 OCR 툴킷입니다.
✅ 웹 크롤링보다 신뢰할 수 있는 대규모 텍스트 데이터 생성 가능
✅ 논문, 법률 문서, 기술 보고서 등 다양한 문서 변환에 최적화
✅ 오픈소스로 제공되며 누구나 쉽게 사용 가능